Uso de un índice de base de datos para el rendimiento de los reportes
3 Tareas
1 h 30 minutos
Escenario
Front Stage quiere investigar el impacto de expandir su capacidad de búsqueda de direcciones para incluir el filtrado de direcciones que comienzan con un número determinado. Conocen un origen de información de dirección real que pueden usar: OpenAddress. A Front Stage le preocupa que, a medida que la tabla de direcciones crezca y se haga un mayor uso de la búsqueda de direcciones, el rendimiento de las consultas podría afectar su capacidad para procesar casos de manera eficiente.
La siguiente tabla incluye las credenciales que necesita para completar el reto.
| Función | Nombre de usuario | Contraseña | Tipo de usuario |
|---|---|---|---|
| Admin | Admin@Booking | reglas | Aplicación |
| pgAdmin4 | pega | pega | Base de datos |
Nota: Este reto solo se puede completar a través de Linux Lite VM, ya que es necesario tener acceso a la base de datos.
Analice el posible impacto en el rendimiento que tendría la expansión de la capacidad de búsqueda de direcciones para incluir el filtrado de direcciones. Para hacer esto, primero inserta una gran cantidad de datos de prueba en la tabla FSG-Data-Address, customerdata.fsg_data_address.
A continuación, prueba una condición de filtro de calles para usar con la fórmula de Haversine. No necesita modificar la regla HaversineFormula de Connect-SQL. En su lugar, ejecute la consulta modificada desde la herramienta PostSQL pdAdmin4. Analice la consulta y agréguele un prefijo usando EXPLAIN (ANALYZE true, COSTS true, FORMAT JSON). Primero ejecute la consulta y observe el resultado. Luego, agregue un índice de base de datos a la columna de calle. Ejecute la consulta de nuevo y compare el resultado de su primera ejecución.
Tareas detalladas
1 Revisar los detalles de la solución
Considere indexar una columna de tabla que se usa como criterio de filtro en la consulta SQL.
2 Configurar la indexación
Para completar la asignación, realice las siguientes tareas.
- Descargue los datos de dirección del siguiente enlace: Excercise.zip (Openaddr Collected US Northeast File).
- Transfiera el archivo .zip al directorio
$/home/architect/Desktop. - Cargue los datos de dirección .csv en la base de datos PostgreSQL usando la herramienta de consulta de pgAdmin4.
- En el archivo Exercise, abra el archivo .sql fsg_data_address_import.sql y ejecute .
- Ejecute la siguiente consulta para verificar que todos los registros se carguen correctamente.
Seleccione count(*) de customerdata.fsg_data_address - En lugar de modificar la fórmula de Haversine agregando un criterio de filtro como AND street LIKE '1 ROGERS STR%', realice una consulta simple dentro de pgAdmin4 contra la tabla de direcciones para analizar estadísticas. La siguiente tabla es un ejemplo.
EXPLAIN (ANALYZE true, COSTS true, FORMAT JSON)
SELECT pyguid AS pyGUID,
reference AS Reference,
isfor AS IsFor,
street AS Street,
city AS City,
state AS State,
postalcode AS PostalCode,
country AS Country,
latitude AS Latitude,
longitude AS Longitude
FROM customerdata.fsg_data_address
WHERE street like '1 ROGERS STR%'; - Verifique las estadísticas para el escaneo secuencial y captúrelas.
- En pr_fsg_data_address, seleccione Indexes (Índices).
- Haga clic con el botón secundario y luego seleccione Create (Crear).
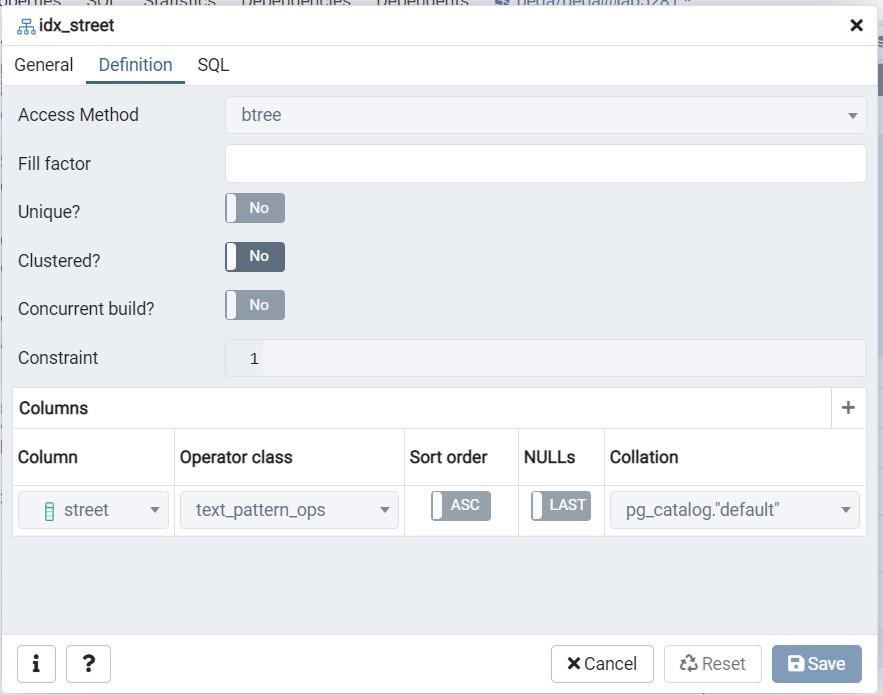
- Proporcione un nombre de índice, como idx_street o StreetIDX.
- En la tabla Definition , seleccione btree.
- Agregue la columna de calle al índice.
- Elija cualquier clase de operador, como text_pattern_ops.
- Repita el paso 6 para ver un rendimiento significativamente más rápido debido al uso de un escaneo de índice.
- Opcional: ejecute la siguiente versión modificada de la consulta de fórmula de Haversine.
EXPLAIN (ANALYZE true, COSTS true, FORMAT json)
SELECT pyGUID AS pyGUID,
Reference AS Reference,
IsFor AS IsFor,
Street AS Street,
City AS City,
State AS State,
PostalCode AS PostalCode,
Country AS Country,
Latitude AS Latitude,
Longitude AS Longitude,
Distance AS Distance
FROM (
SELECT z.pyguid AS pyGUID,
z.reference AS Reference,
z.isfor AS IsFor,
z.street AS Street,
z.city AS City,
z.state AS State,
z.postalcode AS PostalCode,
z.country AS Country,
z.latitude AS Latitude,
z.longitude AS Longitude,
p.radius,
p.distanceunit * DEGREES(ACOS(COS(RADIANS(p.latpoint)) * COS(RADIANS(z.latitude)) * COS(RADIANS(p.longpoint - z.longitude)) + SIN(RADIANS(p.latpoint)) * SIN(RADIANS(z.latitude)))) AS Distance
FROM customerdata.fsg_data_address AS z
JOIN (
SELECT 42.0 AS latpoint,
-71.0 AS longpoint,
30.0 AS radius,
69.0 AS distanceunit ) AS p ON 1 = 1 ) AS d
WHERE distance <= radius
AND street LIKE '1 ROGERS STR%'
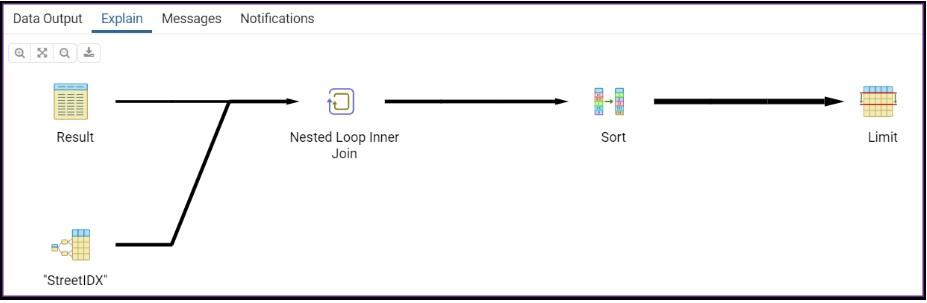
ORDER BY distanceEn la siguiente imagen, se muestra la ejecución de la declaración de explicación de la versión modificada de la fórmula de Haversine.
Nota: Si intenta indexar las columnas de latitud y longitud no mejora el rendimiento, porque estas columnas son numéricas. pgAdmin4 no admite la definición de índices para columnas numéricas. Si se fuerza un índice en una columna numérica usando la sintaxis DDL, por ejemplo, CREATE INDEX idx_lat ON customerdata.fsg_data_address(latitude), no funciona; se ignora el índice. - Verifique que las columnas indexadas den como resultado lecturas de rendimiento significativamente mejoradas.
3 Opcional: compare el rendimiento de la definición de reportes con diferentes orígenes
Para completar la asignación, realice las siguientes tareas.
- Cargue la gran cantidad de datos en el sistema.
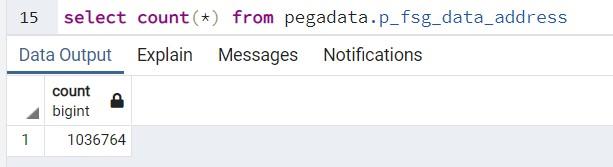
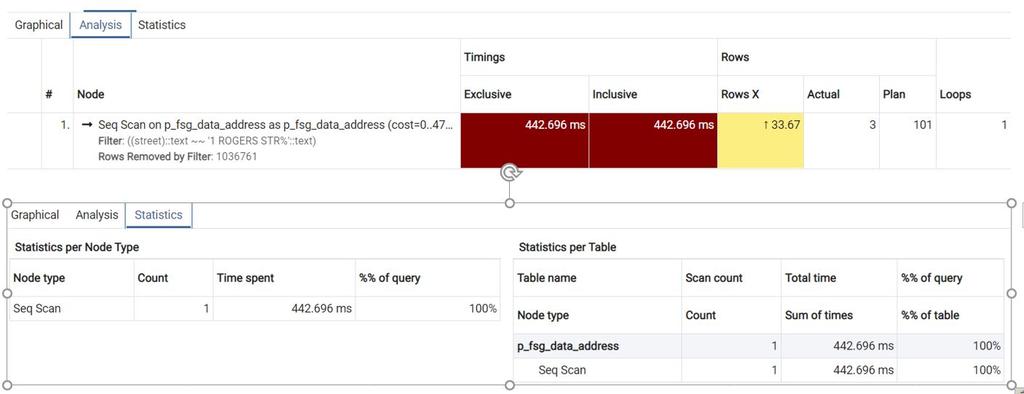
- Ejecute el siguiente plan de consulta siguiente para ver las estadísticas y los análisis.
Plan de consulta Resultado del plan de consulta EXPLAIN (ANALYZE true, COSTS true, FORMAT json)
SELECT pyguid AS pyGUID,
reference AS Reference,
isfor AS IsFor,
street AS Street,
city AS City,
state AS State,
postalcode AS PostalCode,
country AS Country,
latitude AS Latitude,
longitude AS Longitude
FROM pegadata.p_fsg_data_address
WHERE street like '1 ROGERS STR%';
[
{
"Plan": {
"Node Type": "Seq Scan",
"Relation Name": "p_fsg_data_address",
"Alias": "p_fsg_data_address",
"Startup Cost": 0,
"Total Cost": 47526.55,
"Plan Rows": 101,
"Plan Width": 139,
"Actual Startup Time": 128.282,
"Actual Total Time": 417.202,
"Actual Rows": 3,
"Actual Loops": 1,
"Filter": "((street)::text ~~ '1 ROGERS STR%'::text)",
"Rows Removed by Filter": 1036761
},
"Planning Time": 0.241,
"Triggers": [],
"Execution Time": 417.292
}
]
- Ejecute la definición del reporte con los mismos criterios de filtro del plan de consulta.
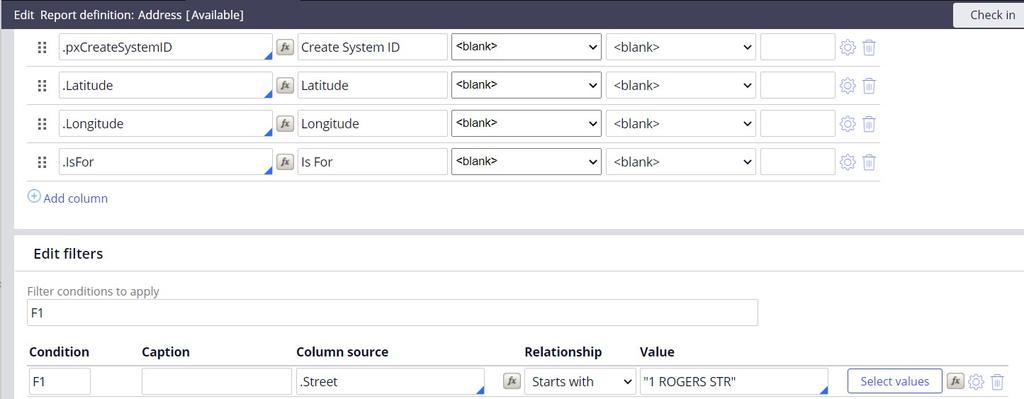
- Verifique que la preferencia de recuperación de datos esté configurada para usar la base de datos (predeterminado).
- Inicie la herramienta Tracer y ejecute la definición del reporte para verificar el tiempo transcurrido en Tracer.
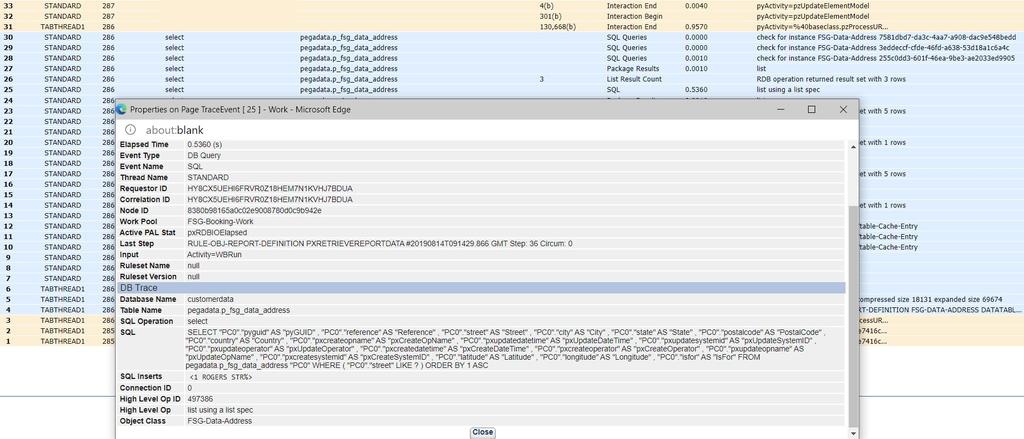
- Cree el índice para las columnas requeridas (por ejemplo, Calle).
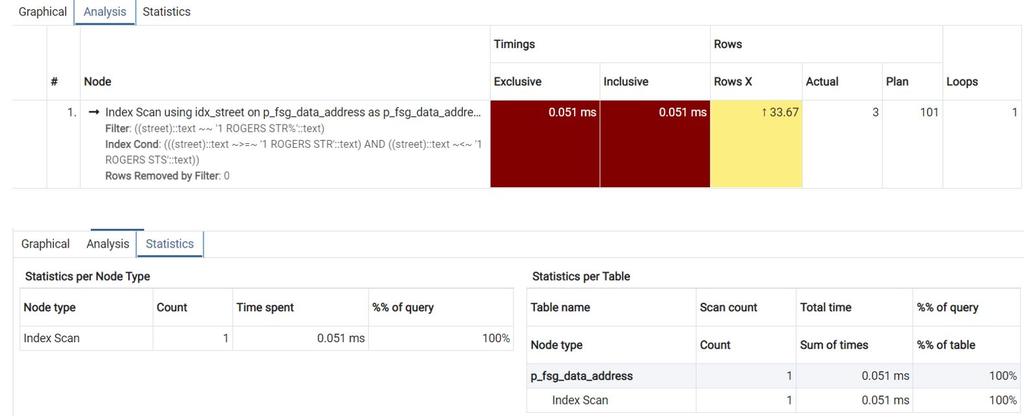
- Después de la creación del índice para la columna, ejecute el plan de consulta para ver el análisis/las estadísticas.
- Inicie la herramienta Tracer y ejecute la definición de reportes configurada anteriormente para ver el tiempo transcurrido en Tracer.
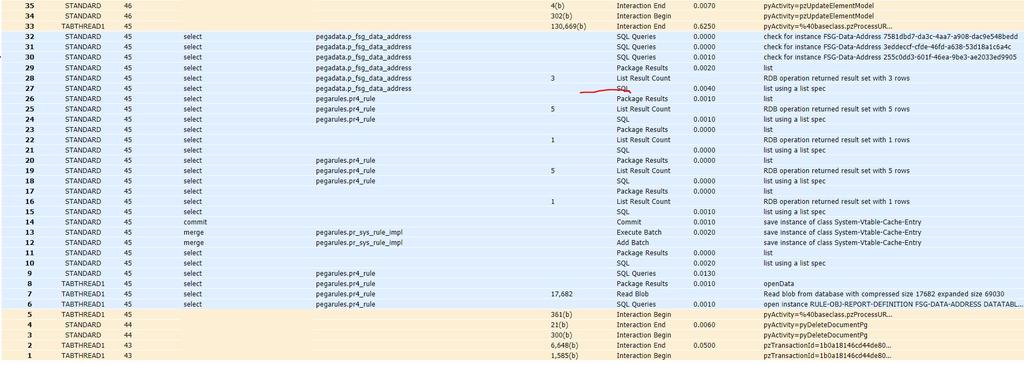
- Compare el tiempo empleado y el tiempo transcurrido para la consulta antes y después de la creación del índice (paso 5 versus paso 8).
- A continuación, pruebe el reporte usando el índice de búsqueda elástico. Deberá modificar el reporte y crear un índice de búsqueda elástico.
- Actualice la preferencia de recuperación de datos de definición de reportes a Prefer elastic search index (Preferir el índice de búsqueda elástica).
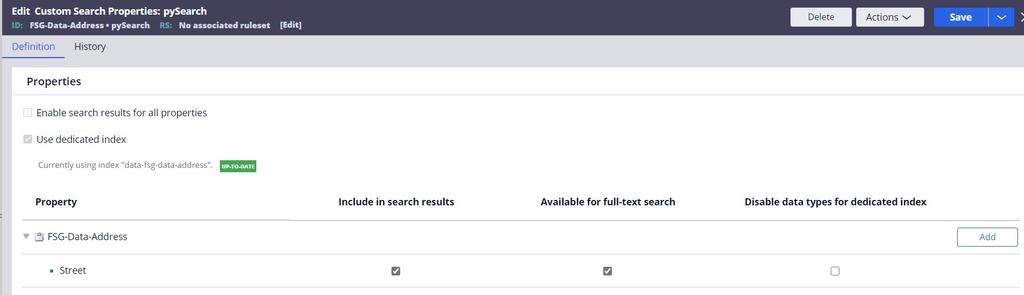
- Cree una regla de propiedad de búsqueda personalizada y agregue la columna/propiedad requerida.
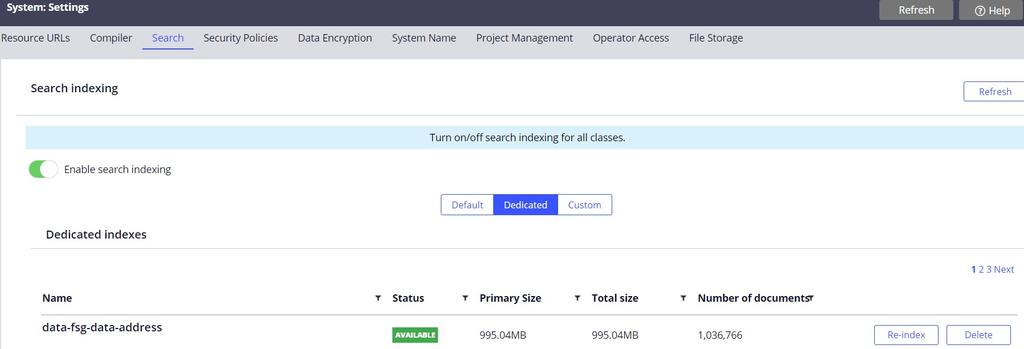
- Cree el índice dedicado.
- Verifique que el índice dedicado requerido esté disponible. De lo contrario, indéxelo o vuelva a indexarlo para que esté disponible.
- Inicie la herramienta Tracer y ejecute la definición del reporte mediante la búsqueda elástica para ver el tiempo transcurrido en Tracer.

- Compare el tiempo transcurrido del final de la interacción de la recuperación de la base de datos frente al índice de búsqueda elástica (paso 8 frente al paso 14).
La definición de reportes que proviene de un índice de búsqueda elástico recupera los resultados más rápido que en el caso de datos obtenidos por una base de datos.
Disponible en la siguiente misión:
If you are having problems with your training, please review the Pega Academy Support FAQs.
¿Quiere ayudarnos a mejorar este contenido?