レポートのパフォーマンスに必要なデータベースインデックスの使用
3 タスク
1時間 30 分
シナリオ
Front Stageでは、住所検索機能を拡張して特定の数字で始まる住所をフィルタリングできるようにした場合の影響を調査したいと考えています。 実際に使える住所情報のソースはOpenAddressであることがわかっています。 Front Stageでは、住所テーブルが大きくなり、住所検索の利用が増えると、クエリーのパフォーマンスがケースを効率的にプロセスする能力を損なわないか懸念しています。
以下の表は、チャレンジに必要なログイン情報をまとめたものです。
| ロール | ユーザー名 | パスワード | ユーザータイプ |
|---|---|---|---|
| Admin | Admin@Booking | rules | アプリケーション |
| pgAdmin4 | pega | pega | データベース |
補足: このチャレンジではデータベースにアクセスする必要があるため、使用できるのはLinux Lite VMのみです。
住所検索機能を拡張して番地のフィルタリング機能を追加した場合のパフォーマンスへの影響を分析してください。 そのためには、まず、大量のテストデータをFSG-Data-Addressテーブルのcustomerdata.fsg_data_addressに挿入します。
次に、Haversine式で使用する番地フィルター条件をテストします。 HaversineFormula Connect-SQLルールを変更する必要はありません。 代わりに、PostSQL pdAdmin4ツールから、変更を加えたクエリーを実行します。 「EXPLAIN (ANALYZE true, COSTS true, FORMAT JSON)」を使用してクエリーを分析し、クエリーにプレフィックスを付けます。 まず、クエリーを実行して、その結果を記録しておきます。 次に、「street」列にデータベースインデックスを追加します。 再度クエリーを実行し、最初に実行したときの結果と比較します。
詳細なタスク
1 ソリューション詳細のレビュー
SQLクエリーでフィルター条件として使用されるテーブルの列にインデックスを付けることを検討します。
2 インデックスの構成
アサインメントを完了するために、以下のタスクを行ってください。
- 次のリンクからアドレスデータをダウンロードします:Excercise.zip(Openaddr Collected US Northeast File)。
- .zipファイルを
$/home/architect/Desktopの辞書に転送します。 - pgAdmin4のクエリーツールを使って、.csv形式の住所データをPostgreSQLデータベースに読み込みます。
- Exerciseファイルで、.sqlファイルfsg_data_address_import.sql を開き、実行します。
- 次のクエリーを実行して、すべてのレコードが正常に読み込まれることを確認します。
Select count(*) from customerdata.fsg_data_address - 「AND street LIKE '1 ROGERS STR%'」などのフィルター条件を追加してHaversine式に変更を加える代わりに、pgAdmin4内で住所テーブルに対して単純なクエリーを実行し、統計を分析します。 以下の表はその一例です。
EXPLAIN (ANALYZE true, COSTS true, FORMAT JSON)
SELECT pyguid AS pyGUID,
reference AS Reference,
isfor AS IsFor,
street AS Street,
city AS City,
state AS State,
postalcode AS PostalCode,
country AS Country,
latitude AS Latitude,
longitude AS Longitude
FROM customerdata.fsg_data_address
WHERE street like '1 ROGERS STR%'; - シーケンシャルスキャンの統計情報を検証して取り込みます。
- pr_fsg_data_addressで、「Indexes」を選択します。.
- 右クリックして、「Create」を選択します。
- 「idx_street」、「StreetIDX」などのインデックス名を指定します。
- Definition テーブルで、「btree」を選択します。
- 「street」列をインデックスに追加します。
- text_pattern_opsなどの任意のオペレータークラスを選択します。
- 手順6を繰り返して、インデックススキャンを使用したことでパフォーマンスが大幅に向上することを確認します。
- オプション:以下の変更を加えたHaversine式クエリーを実行します。
EXPLAIN (ANALYZE true, COSTS true, FORMAT json)
SELECT pyGUID AS pyGUID,
Reference AS Reference,
IsFor AS IsFor,
Street AS Street,
City AS City,
State AS State,
PostalCode AS PostalCode,
Country AS Country,
Latitude AS Latitude,
Longitude AS Longitude,
Distance AS Distance
FROM (
SELECT z.pyguid AS pyGUID,
z.reference AS Reference,
z.isfor AS IsFor,
z.street AS Street,
z.city AS City,
z.state AS State,
z.postalcode AS PostalCode,
z.country AS Country,
z.latitude AS Latitude,
z.longitude AS Longitude,
p.radius,
p.distanceunit * DEGREES(ACOS(COS(RADIANS(p.latpoint)) * COS(RADIANS(z.latitude)) * COS(RADIANS(p.longpoint - z.longitude)) + SIN(RADIANS(p.latpoint)) * SIN(RADIANS(z.latitude)))) AS Distance
FROM customerdata.fsg_data_address AS z
JOIN (
SELECT 42.0 AS latpoint,
-71.0 AS longpoint,
30.0 AS radius,
69.0 AS distanceunit ) AS p ON 1 = 1 ) AS d
WHERE distance <= radius
AND street LIKE '1 ROGERS STR%'
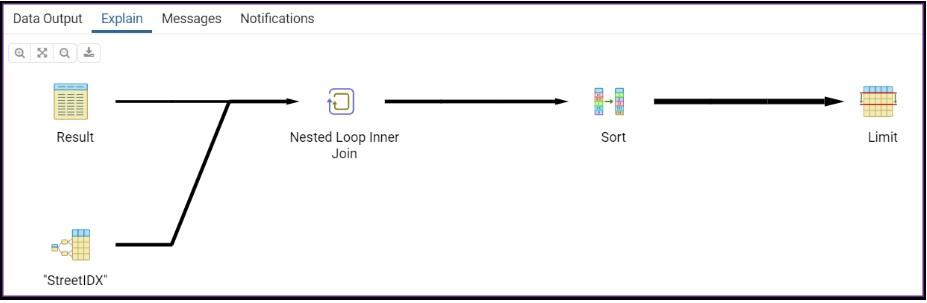
ORDER BY distance次の画像は、変更を加えたHaversine式のステートメント実行の概略を示しています。
補足: 緯度と経度の列は数値であるため、インデックスを作成してもパフォーマンスは向上しません。pgAdmin4は、数値の列のインデックスの定義をサポートしていません。 「CREATE INDEX idx_lat ON customerdata.fsg_data_address(latitude)」のようなDDL構文を使用して数値の列にインデックスを強制しても、そのインデックスは無視されるため、動作しません。 - インデックス付きの列を使用するとパフォーマンスが大幅に向上することを確認します。
3 オプション:レポートディフィニッションのパフォーマンスを異なるソースで比較
アサインメントを完了するために、以下のタスクを行ってください。
- 大量のデータをシステムに読み込みます。
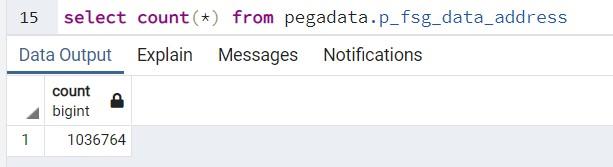
- 以下のクエリープランを実行して、統計と分析結果を表示します。
クエリープラン クエリープラン出力 EXPLAIN (ANALYZE true, COSTS true, FORMAT json)
SELECT pyguid AS pyGUID,
reference AS Reference,
isfor AS IsFor,
street AS Street,
city AS City,
state AS State,
postalcode AS PostalCode,
country AS Country,
latitude AS Latitude,
longitude AS Longitude
FROM pegadata.p_fsg_data_address
WHERE street like '1 ROGERS STR%';
[
{
"Plan": {
"Node Type": "Seq Scan",
"Relation Name": "p_fsg_data_address",
"Alias": "p_fsg_data_address",
"Startup Cost": 0,
"Total Cost": 47526.55,
"Plan Rows": 101,
"Plan Width": 139,
"Actual Startup Time": 128.282,
"Actual Total Time": 417.202,
"Actual Rows": 3,
"Actual Loops": 1,
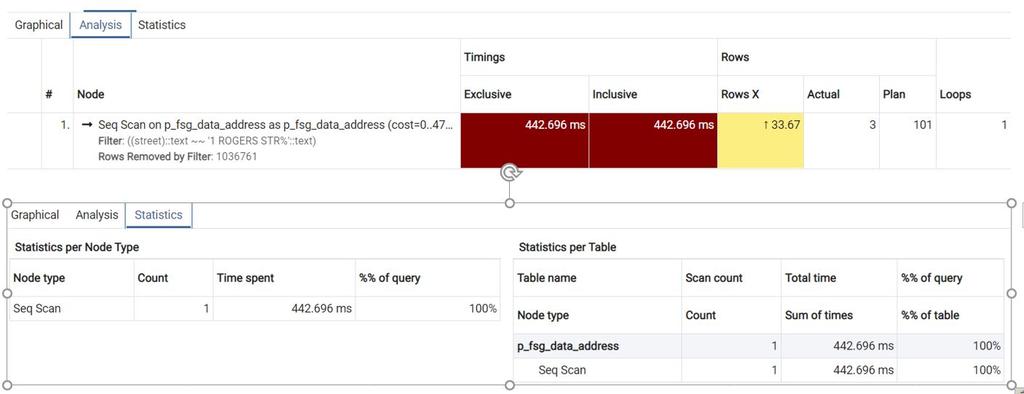
"Filter": "((street)::text ~~ '1 ROGERS STR%'::text)",
"Rows Removed by Filter": 1036761
},
"Planning Time": 0.241,
"Triggers": [],
"Execution Time": 417.292
}
]
- クエリープランと同じフィルター条件でレポートディフィニッションを実行します。
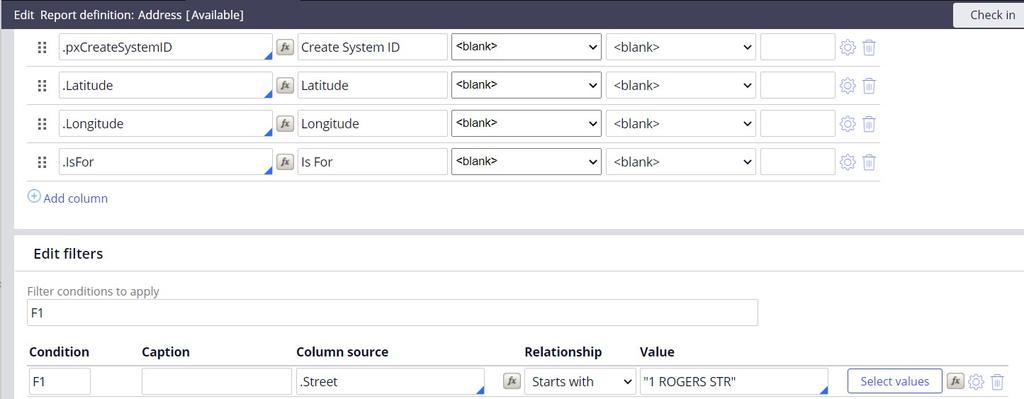
- 「Data retrieval preference」が「Use the database (default)」に設定されていることを確認します。
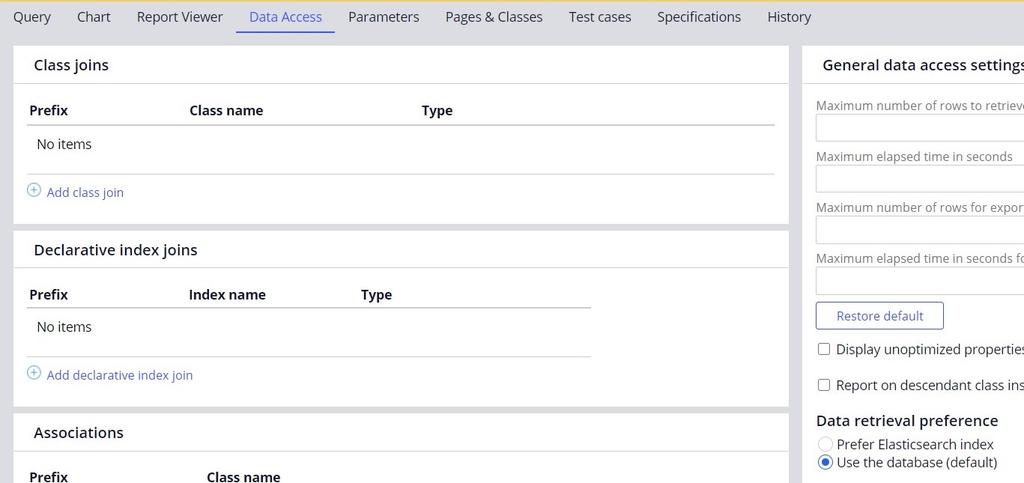
- Tracerツールを起動し、レポートディフィニッションを実行して、Tracerで経過時間を確認します。
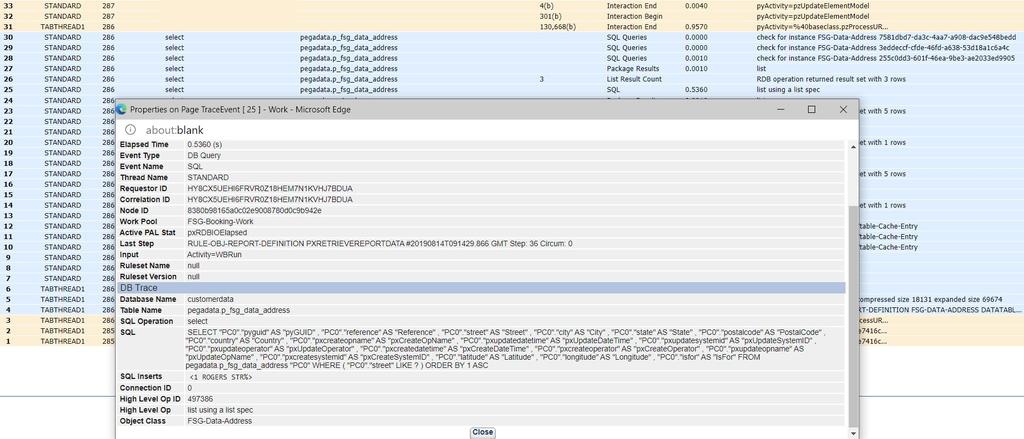
- 必要な列(「Street」など)のインデックスを作成します。
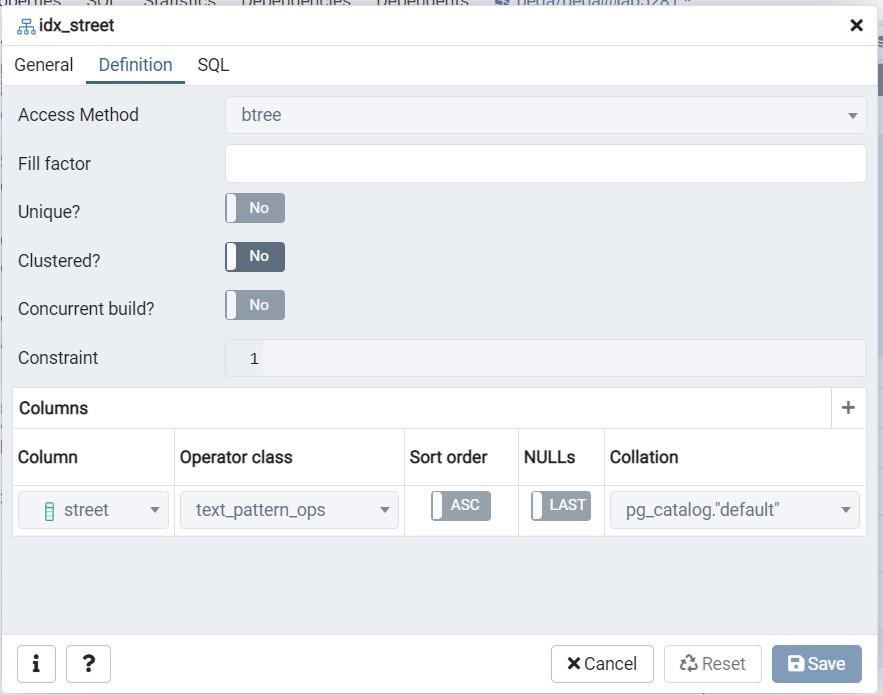
- 列のインデックスを作成した後、クエリープランを実行して分析と統計を表示します。
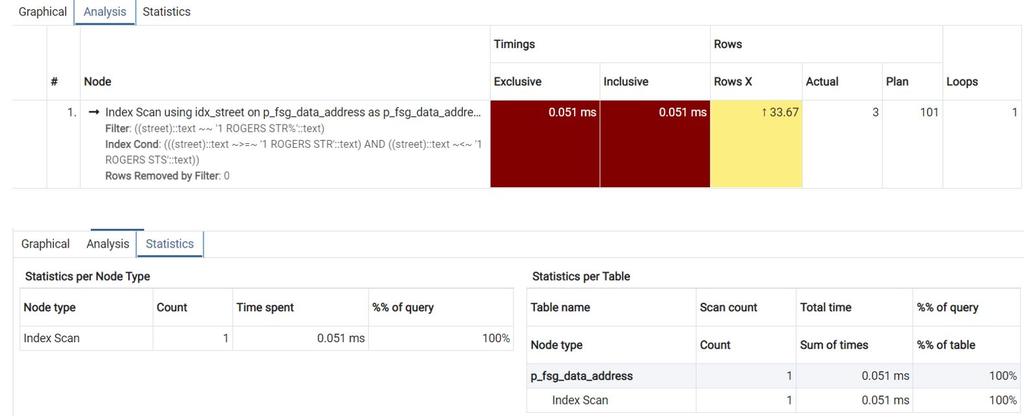
- Tracerツールを起動し、先に構成したレポートディフィニッションを実行して、Tracerで経過時間を表示します。
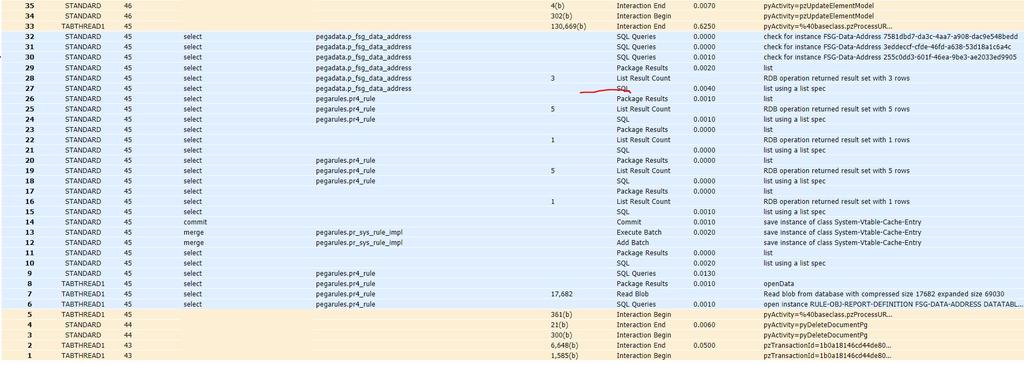
- インデックス作成前後でクエリーにかかった時間と経過時間を比較します(手順5と手順8)。
- 次に、エラスティック検索インデックスを使ったレポートを試します。 レポートに変更を加えてエラスティック検索インデックスを作成する必要があります。
- レポートディフィニッションのデータ取得優先順位を「Prefer elastic search index」に更新します。
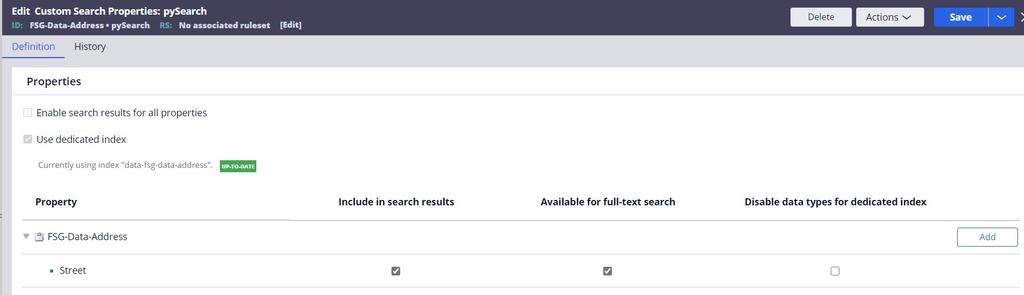
- カスタム検索プロパティルールを作成し、必要な列とプロパティを追加します。
- 専用インデックスを作成します。
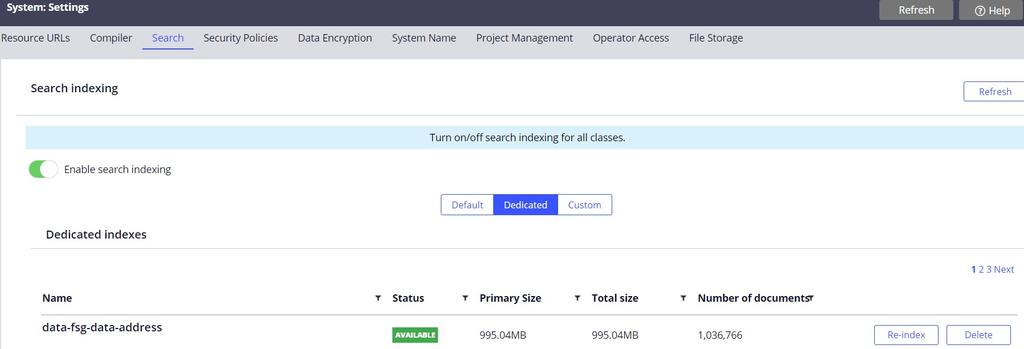
- 必要な専用インデックスが利用可能であることを確認します。 利用可能でない場合は、インデックスを作成するか、再作成して利用できるようにします。
- Tracerツールを起動し、エラスティック検索を使用してレポートディフィニッションを実行し、Tracerで経過時間を確認します。

- データベース取得のインタラクション終了時とエラスティック検索インデックスの経過時間を比較します(手順8と手順14)。
エラスティック検索インデックスをソースとしたレポートディフィニッションは、データベースをソースとした場合よりも短時間で結果を取得できます。
このモジュールは、下記のミッションにも含まれています。
If you are having problems with your training, please review the Pega Academy Support FAQs.