データモデルのベストプラクティス
データモデルのベストプラクティス
データクラスを具象クラスではなく抽象クラスと宣言する作業は、以前はもっと厳密でした。 抽象クラスと宣言したら、そのクラス名には末尾にハイフンを付ける必要がありましたが、 今やその必要はありません。
「抽象」や「具象」は、Java言語からの借用語です。 抽象クラスとは、継承だけが可能で、構築はできないクラスです。 Javaでは、new()演算子を使って抽象クラスを作成しようとすると、コンパイルエラーになります。
Pegaが使用する抽象クラスの例としては、BookingアプリケーションのFSG-Data-Locationクラスが挙げられます。 Pegaでは、ActivityでPega-Newを使用するか、データトランスフォームを使用してFSG-Data-Locationのステップページにプロパティを設定するだけで、クリップボード上にFSG-Data-Locationページを自由に作成できます。
現在、Pegaでは「抽象」と「具象」を主に区別しており、「抽象」はデータクラスがキーを定義していないことを意味します。 キーを定義していないデータクラスは、データベーステーブルに保存できません。
新しいCustomerDataスキーマでは、データベーステーブルにPega固有の列を含める必要がなくなりました。 pzInsKeyをプライマリーキーとする必要があるPegaDataおよびPegaRulesスキーマテーブルとは異なり、CustomerDataスキーマテーブルではpzInsKeyをプライマリーキーとして使用することはありません。 Pega 7.3以降、Rule-Obj-Classルールにはチェックボックスがあります。 このチェックボックスを選択すると、pyGUIDがプライマリーキーとして使用され、保存されるレコードがまだpyGUIDの値を受け取っていない場合は自動的に値が生成されます。
具象データクラス
「具象」データクラス内の情報は、ケースの外部で永続化されるよう設計されています。 履歴データの取得のために、具象データをケースにコピーすることは許容されます。 このようなコピーが発生すると、履歴情報は、BLOBとして知られるケースのpzPvStream列内に埋め込まれます。 履歴データは、ケースBLOBの外部に保存することもできます。 このような場合は、データクラス名の最後に「-History」を付けると、そのデータクラスが何を表しているのかを理解しやすくなります。 BLOB内にデータを保存してからDeclare Indexを定義してデータを公開するのではなく、継承やレポートの観点からBLOBの外部にデータを保存することにはメリットがあります。 Declare IndexクラスのベースはData-ではなく、Index-になります。
「Reference Data」とは、その名のとおり、参照されるために永続化された特殊なデータの名称です。 Referenceデータの用途としては、ドロップダウンリストの値を入力することが考えられます。 一般的に、Referenceデータクラスには、他のデータインスタンスへの参照がないか、ごくわずかしかありません。
パッケージ化の観点からは、参照データは「アトミック」、「自己完結型」、「カプセル化」、「デッドエンド」のいずれかとみなすことができます。相互参照するデータインスタンスのネットワークは、全体としてパッケージ化された後、別の環境にデプロイされ、アプリケーションを実行する前にその環境を初期化できます。 ネットワークパッケージ化が可能なデッドエンドのデータインスタンスの例としては、FSG-Data-AddressがFSG-Data-Locationを参照し、それがFSG-Data-Contactを参照していることが挙げられます。 Location情報は、静的情報です。 Location情報は、使用する前であればいつでも作成できます。 Bookingアプリケーションの複数のBookEventケースは、同じFSG-Data-Venueインスタンスを参照できます。 そのVenueインスタンスは、他のFSG-Data-Locationインスタンスと同じCustomerDataスキーマテーブルに保存されます。
要件がない限り、Reference Dataインスタンス全体をケースのBLOB内にコピーして永続化しないでください。 データをコピーする理由のひとつは、値が一時的なものであることです(例:価格)。 時間の経過とともに、商品価格は変化します。 データインスタンス全体のコピーは、履歴監査のために作成できます。
履歴データをコピーする場合は、そのデータを取得するために使用した(つまり、その特定のデータにアクセスした理由)ルックアップ値を永続化することも重要です。 たとえば、FSG-Data-Pricingレコードを永続化する場合には、ItemID、Reference、Price情報が記録されるだけでなく、Quantity、Bit、Discount Factorなどの入力も記録されます。 このようにすれば、将来、その入力を用いて履歴から同じ価格を再び導き出すことができます。 将来、FSG-Data-PriceにAsOfDate列が追加された場合は、FSG-Data-Pricingは、FSG-Data-Priceを照会する際に使用した日付値を記録する必要があります。 過去の価格をコピーすることで、その価格が保存されたときと同じ計算を行う必要がなくなるため、パフォーマンスが向上します。 請求書に多数の明細項目があるとします。
計算の必要がなければ、ケースのBLOBに埋め込む(Snapshotパターン)のではなく、ケースからReference DataへのLookup(SORパターン)またはJOINを行う方が合理的です。 例として、名前の保存が挙げられます。 名前は時間の経過とともに変更される可能性があります。これはPegaによる管理の範囲外ですが、 生成された一意のIDに関しては管理できます。 名前はキーとして使用しないでください。 名前をもとにクエリーを実行すると、1行で返されるとは限りません。
抽象データクラス
抽象クラスの例として、HotelアプリケーションとHotelProxyアプリケーションが共有するComponentルールセットクラス、FSG-Data-Hotel-RoomsRequestが挙げられます。 FSG-Data-Hotelは、エンタープライズレベルで定義された抽象Referenceデータクラスです。 Data Typeウィザードを使用して新しいデータタイプを定義する場合は、具象クラスを含む既存のデータタイプを選択できます。 Data Typeウィザードは、ユーザーが入力した名前(例:「RoomsRequest」)を、ダッシュ(「-」)を区切り文字として使い、既存のクラス名(例:「FSG-Data-Hotel」)に追加します。 パターン継承クラス名が作成されます。
FSG-Data-Hotel-RoomsRequestはHotelアプリケーションとHotelProxyアプリケーション間の統合にのみ使用されるため、永続化されることはありません。 Hotelアプリケーションのデータベースにデータインスタンスを保存しても、HotelProxyアプリケーションにはメリットがなく、その逆も同様です。
データがケースと密接に結合している(そのため埋め込み可能)もう1の例は、データクラスがケース自体と実質的に同義である場合です。 データクラスの目的は、ケースがトランザクションのシステムオブレコード(SOR)としての役割を果たす際に支援することです。 データクラスは、セクション、ビュー、データトランスフォームなどの特定のルールを再利用できるようにすることでその目的を果たします。 複数のケースタイプは、同じデータクラスを同じように(例:抽象クラスとして)使用できます。
こうした複数のケースタイプは、そのデータクラスの具象インスタンスを参照する必要はありません。 データクラスは、ケースレベルのプロパティの作成数を最小限に抑えます。 あるケースが持つスカラープロパティの数が多いほど、ケースの維持は難しくなります(例:スカラープロパティXの用途や、 スカラープロパティYの用途など)。
複数のケースタイプが同じフィールドグループやフィールドグループリストのプロパティを埋め込んでいる場合には、そのプロパティをワークプールクラスに移動させたくなります。 しかし、データモデル分析が適切に行われていれば、その必要はありません。 複数のケースタイプが同じフィールドグループやフィールドグループリストのプロパティを使用している場合は、そのプロパティが兄弟アプリケーションにも利用できる可能性が高くなります。 ベストプラクティスとしては、このプロパティを組み込みアプリケーション内で定義することです。 現在のアプリケーション自体を、共有の組み込みアプリケーション上に構築された兄弟アプリケーションに分解することはなくなります。
デメテルの法則
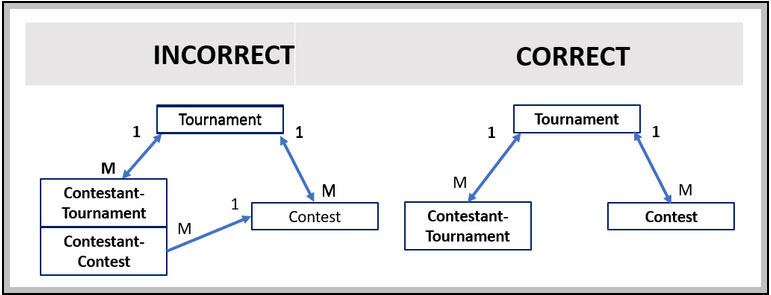
Contestantには、Tournament内で各Contestを「操作する」方法が必要です。 ただし、並行処理の問題があります。 ContestantがContestケースに直接アクセスできるよう許可されている場合、1つのContestantのみがContestケースを一度に更新できます。 セキュリティの実施をより複雑にし、ケースがロックされて、後でもう一度試すよう伝えられる顧客にとっては低いユーザーエクスペリエンス(UX)です。
代わりに、Contestantは、ORG-Data-Contestant-Contestインスタンスの中で選択できます。 クラスの-Contest部分はLink-クラスに類似します。 ContestRefプロパティはContestケースを指します。 2番目のプロパティであるContestantRefはContestantを指します。 しかし、「デメテルの法則」によれば、これは誤りではありません。
デメテルの法則によると、同じオブジェクトへの冗長なパスは避けるべきです。 TournamentケースがContestを削除するようであれば、Contestant-Contestインスタンスは、ContestがすでにTournamentに関連付けられていないにもかかわらず、削除されたContestを指します。
このシナリオは、Contestantが何のContestがアクティブかを知るための「API」を、Tournamentケースが提供することを示唆しています。
クエリーは次を検索します。
- ContestantおよびTournamentケースの両方を参照するContestant-Tournamentインスタンス
- pxCoverInsKeyがTournamentケースのpzInsKeyと同じものであるContestインスタンス
エンタープライズレベルのデータクラスとアプリケーションレベルのデータクラスの比較
組織のビジネスの中枢を担うデータクラスは、すべてエンタープライズレイヤーで定義するのがベストプラクティスです。 あるデータクラスが組織の中枢を担っているとします。 その場合は、同じクラスを使用する兄弟アプリケーションを開発できる可能性が高くなります。 同じ組織内の2つのPegaアプリケーションに、統合とデータトランスフォームによる情報共有を強制しても意味がありません。 データクラスを同じものにすべきです。 これは、すべてのアプリケーションがData-PartyのようなPegaデータクラスを使用するよう期待することと変わりません。
アプリケーションに、エンタープライズレベルのデータクラスに追加したいプロパティ(他のアプリケーションには適用されないプロパティ)がある場合は、アプリケーションはエンタープライズレベルのデータクラスを直接継承して、それらのプロパティを自由に追加できます。 解放/閉鎖の原則によれば、エンタープライズレベルで動作するものは、エンタープライズアプリケーションから見て、アプリケーションレベルでも同じように動作するはずです。 エンタープライズアプリケーションは、アプリケーションレベルで具体的に何らかの動作が生じても反応しません。「X」機能が実行された場合にのみ反応します。
時には、アプリケーションがそのアプリケーション固有のデータクラスを定義し、再利用レイヤーで定義された非Pegaデータクラスを継承しないこともあります。これは、他のアプリケーションが同じデータクラスを使用する必要がない場合に発生します。
データクラスの命名
一般的に、ケースは、その主要なペイロード(ケースが管理するデータ)を、そのクラスと同義のデータ構造内に取り込みます。 ケース名は名詞でも構いませんが、一般的には、BookEventのように、動作 + 名詞、または名詞 + 動作といったパターンでケース名を付けます。 このスタイルを適用する理由は、Eventなどの同じ名詞は複数のケースタイプによって処理される可能性があるためです。 たとえば、EventBillingは、Eventデータを操作する2つ目のケースタイプにもなり得ます。
ケースが管理する名詞に、DetailsやInformationを付ける必要はありません。 名詞は、オブジェクトが何なのかを示すモデルです。その目的は、実世界のオブジェクトに関する詳細や情報をカプセル化することです。 クラス名で内こうした要素を反復する必要はありません。 冗長化は避けましょう。
プロパティ名内でそのプロパティの所有クラス名を反復すると、冗長化を招くため、適切ではありません。 たとえば、FSG-Data-EventデータクラスのプロパティにEventStartDateいう名前は付けられません。 プロパティがイベントと関連していることはわかっています。 プロパティにStartDateという名前を付けてください。
同様に、BookEventの場合は、FSG-Data-Event EventDetailsフィールドグループプロパティは必要ありません。 Eventだけで十分であり、Detailsを追加する必要はありません。
最後になりますが、そのEventフィールドグループのデータクラスには、FSG-Data-EventDetailsという名前は付けないでください。 「Details」という文言は有用でないどころか、 Detailsを追加することで、データモデルが余計に理解しにくくなります。 Detailsを追加するということは、追加すべき何らかの理由があるということです。 たとえば、詳細を含まない他のEventクラスが存在するといったことです。 データクラスには、FSG-Data-Eventという名前を付けてください。
データの冗長化の回避
データの完全性は、同じデータを2か所にではなく1か所に保存するという「信頼できる唯一の情報源」原則を守ることで維持できます。 この原則が、データベース正規化技術の根拠となっています。何よりもまず、「関係の集合を、望ましくない挿入、更新、削除の依存関係から解放すること」(Edgar F. Codd, 1970)です。 同じデータ、あるいはその派生データ(Promoter Score Categoryなど)が複数の場所に保存されているとします。 元のデータが変更されたらどうなるでしょうか。 値が変更されるたびに、アプリケーションに同じ値の保存先をすべて追跡して更新することが求められるようなら、メンテナンスが複雑化し、保守性が低下します。 Rule-Declare-Triggerには、複数のロックされたインスタンスを同時に処理する必要があることを考えてみましょう。
データエクセレンスに関するウェビナー
データモデルの詳細については、以下のリンクを参照してください。Data Excellence Webinar
このトピックは、下記のモジュールにも含まれています。
If you are having problems with your training, please review the Pega Academy Support FAQs.