
データベースの問題の診断
データベースの問題は、アプリケーションのパフォーマンスに影響を与える可能性があります。 データベースにどのようにアクセスして使用するかがパフォーマンスの問題の原因となることは少なくありません。 データベースのパフォーマンス問題の根本原因を突き止めるには、データアクセスパターンやトランザクションの境界がデータモデルにどのように影響しているのかを分析します。
たとえば、パフォーマンスの問題は、以下が原因で発生する可能性があります。
- データベーステーブルのサイズ。
- 過剰な数のインデックス。
- BLOBの読み取り。
- 適切に記述されていないSQL文とクエリー。
データベース関連のパフォーマンスの問題には、複数の原因が考えられます。 たとえば、大文字と小文字を区別するフィールドで大文字と小文字を区別しないクエリーを実行するモバイルアプリは、ケース解析実績は多いものの、テーブルサイズが大きく、クエリーの記述が不適切なものの例です。
補足: ベストプラクティスは、アプリケーションの設計をサポートするように、主要なデータ列にインデックスを作成することです。
以下のインタラクションで理解度をチェックしてください。
データベース問題の診断
データベースの問題は、アプリケーションのパフォーマンス低下として表れることがあります。 データベースの問題を診断する前に、兆候を具体的に把握します。 パフォーマンスの低下について報告したユーザーから、低下する前の状況を説明してもらいます。 たとえば、ユーザーは顧客からの問い合わせ画面を開いたときのみにパフォーマンスの低下を感じ、他のプロセスの速度は通常どおりであるかもしれません。
Dev Studioで利用可能なパフォーマンスツールを使用して、データベースの問題を診断します。
補足: プロパティを公開したり、データベーステーブルを新規作成してレコードを移動したりするなど、データベーススキーマを変更する場合は、事前にデータベース管理者(DBA)に相談してください。
Performance Analyzer(PAL)を使用した問題の診断
データベースの問題に起因するパフォーマンスの問題を診断するには、「Configure > System > Performance > Performance Analyzer (PAL)」を選択します。 PALを実行し、画面ごとに段階的に読み取ることで、プロセスのどこで問題が発生しているかを特定し、そのステップの概要まで掘り下げていくことができます。
問題が発生しているユーザーのMy Performance Detailsレポートを確認することもできます。 My Performance Detailsレポートは、特定のセッションで特定のユーザーに起こったことをPALのようなスナップショットで表示します。 Configure > System > Performance > My Performance Detailsをクリックすると、レポートが表示されます。 レポート上でオペレーターIDを変更すると、該当するユーザーのセッションデータが表示されます。
Requestor Performance AnalyzerのFULL ビューを示した次の画像で「+」アイコンをクリックすると、発生する可能性のあるパフォーマンスの問題を特定するために使用できる情報の種類が表示されます。
補足: PAL Snapshotの詳細については、「Profiling your requester session」を参照してください。
コンテキストに応じたパフォーマンスの統計を見ることができます。 どのくらいの頻度で、どのような状況で問題が発生しているのかを特定する必要があります。 たとえば、10,000件のインタラクションのプールでしきい値を超えたリクエストが45件ある状態は、70件のプールでしきい値を超えたリクエストが45件ある状態ほど重大ではありません。
次の画像は、PAL詳細スナップショットのRequestor Summaryの例を示しています。 サーバーインタラクションの数、データベースの時間しきい値、時間しきい値を超えたデータベースリクエストの数に注目してください。 この例では、データベースリクエストの約5%が時間しきい値を超えています。

補足: しきい値を超えた場合には、その都度アラートが表示されます。 アラートは違反を通知しますが、必ずしも原因を示すものではありません。
Database Traceを使用した問題の診断
Database Traceを使用して、データベースに対して行われたクエリーを調べることができます。 たとえば、Dev Studioで「Configure > System > Performance > Database Trace」をクリックし、結果をreadBlob操作でソートして、BLOBからデータを読み取る操作を特定します。 アプリケーションルールセットのルールを調べて、正しいルールが参照されていることを確認してください。
次の画像は、すべてのreadBlob 操作を表示するDatabase Traceの結果を示しています。
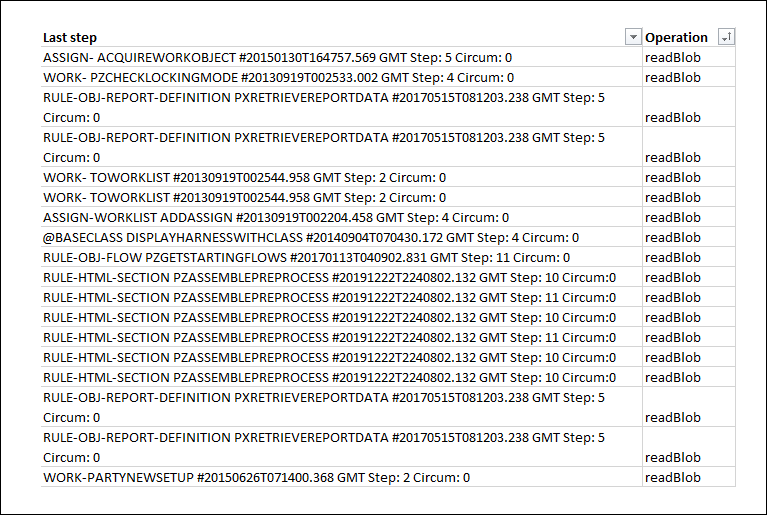
問題への対処のベストプラクティス
パフォーマンステストを頻繁に行うと、診断結果に基づいて問題を早期に解決できます。 見つかった問題のタイプに基づいて、パフォーマンスのチューニングの詳細を確認します。
大規模なデータベーステーブルによる問題
サイズの大きいデータベーステーブルは、そのボリュームがパフォーマンスに影響を与えます。 データベーステーブルが大きいほど、データベースからのデータにアクセスするのに時間がかかります。 たとえば、ある保険会社は1日に数百件のクレームを処理します。 解決されるクレーム案件は膨大な数になります。 1年以内に、ケースワーカーが未解決のケースを検索する際の応答時間が通常よりも遅くなります。
データベーステーブルのサイズが大きい問題に対処するためのオプションは次のとおりです。
- サイズの大きいテーブルがクラスグループにマッピングされている場合は、クラスグループ内の1つ以上のクラスのデータベーステーブルレコードを作成します。 たとえば、あるアプリケーションが5種類のケースを作成する場合を考えてみます。 作成されたケースの半分は、1つのケースタイプです。 最も使用されるケースタイプに別のデータベーステーブルを割り当てることで、クラスグループのテーブル成長率を低下することができます。 クラスグループの詳細については、「Working with class groups」を参照してください。
- テーブルが
pr_otherの場合は、データベーステーブルレコードを作成して、1つ以上の特定クラスのインスタンスを別のテーブルにマッピングします。 次に、クラスインスタンスをpr_otherから適切なテーブルに移動します。pr_otherテーブルを使用すると、PEGA0041アラートとガードレールワーニングがトリガーされるため、開発時に対処するのが最適です。 - リストレポートのページングを有効にして、レポートのパフォーマンスを向上させます。 ページングは、リストレポートが表示する結果の数を、設定した特定のページサイズに制限します。 また、ページングを行うことで、クリップボードのサイズが縮小され、各結果ページの表示にかかる時間も短縮されます。 ユーザーは次のページに移動して、他の結果を見ることができます。
- 主要データ列にインデックスを付けます。
- 不要になったデータをアーカイブします。
データベースサイズに影響を与えるBLOBの問題
BLOBからの読み取りは、アプリケーションがBLOBを展開して必要なデータを取り出すためにメモリを割り当てる必要があるため、パフォーマンスに影響を与えます。 アプリケーションがBLOB全体を読み取り、展開し、必要なプロパティを抽出してからBLOBを破棄する必要があるリクエストは、データベーステーブルの列から値を読み取るリクエストよりも時間がかかります。

たとえば、データページでは、ドロップダウンリストに表示する値のリストをデータベースに問い合わせるレポートディフィニッションを使用してデータを取得することができます。 BLOBに格納されたデータを読み取ると、クエリー時間が所定のパフォーマンスしきい値を超え、PEGA0005: Query time exceeds limitなどのパフォーマンスアラートがトリガーされる場合があります。
BLOBの問題に対処する際の最初のステップは、プロパティが独自の列で公開する必要があるかどうかを判断することです。 BLOBからの読み取りによるパフォーマンスへの影響を評価するまでは、プロパティの公開は避けてください。 BLOBを使用すると、公開されていないデータを圧縮することで、テーブルの行のサイズを縮小することができます。 プロパティを不必要に公開すると、データベーステーブルのサイズが大きくなります。
SQLクエリーにおける問題
SQLクエリーが適切に記述されていないと、Pega Platform™は不必要にデータベースからアイテムを読み込まなければならないため、パフォーマンスに影響が生じます。 SQLクエリーが適切に記述されない問題は、SQLコネクターまたはレポートのいずれかで発生する傾向があります(不要な大文字と小文字を区別するクエリーを実行するSQLルールがその例です)。
Database Traceで特定のクエリーに時間がかかっていると報告された場合は、SQLクエリーの構造に注目してください。 Database Traceデータから置換値と一緒にクエリーをコピーします。次に、データベースのネイティブツールを使ってクエリーを分析し、最適化する方法を検索します。
発生する可能性のある問題の解決策については、次の表を参照してください。
| 発生する可能性のある問題 | 解決策候補 |
|---|---|
|
|
starts withなどの、よりコストのかからない条件を検討します。 |
insert またはupdate 文が含まれているSQLクエリー |
ストレージの最適化を検討します。 |
| 無関係なインデックス | インデックスの数が多すぎると、insert/updateステートメントが遅くなり、パフォーマンスが悪化することがあります。 必要なインデックスだけを使用してください。 |
| SQLクエリーによる2つのテーブルの結合 | Rule-Declare-Indexを作成してパフォーマンスを向上させます。これは、アクセス速度を上げるためにインデックスインスタンスを自動的に維持します。 Declare Indexルールの詳細については、「Configuring Declare Index rules」を参照してください。 |
| クエリーの応答時間 | データベースクエリーの応答時間が、Pega Platformアラートによって定義されたサービスレベルアグリーメント(SLA)の範囲に収まっていることを確認し、必要に応じて調整します。 また、Predictive Diagnostic Cloud(PDC)で他のデータベース関連のアラートを調べます。 PDCの詳細については、「Predictive Diagnostic Cloud」を参照してください。 |
| 列のデータ | データベースクエリーが適切な列からデータを取得し、必要な列以外のデータを含めないようにしてください。 |
| 複数の実行 | 同じデータベースクエリーが複数回実行されたり、必要以上に繰り返されたりしていないことを確認します。これを行うには、PDCまたはPALの読み取り値で実行回数を追跡します。 |
補足: ベストプラクティスは、応答時間(RDB I/O Elapsed)とカウント(RDB I/O Count)を照会する最も複雑なクエリーを見つけて、それらに対処することです。
クリップボードのサイズ
サイズの大きいデータベーステーブルがクリップボードに与える影響は、パフォーマンスの問題の原因の1つです。 Pega Platformのメモリはすべてのリクエスターのクリップボードを格納するため、クリップボードのサイズが大きいと、パフォーマンスに悪影響が及びます。 ページングは、リストレポートが表示する結果の数を、設定した特定のクリップボードページのサイズに制限します。 ページングを行うことで、クリップボードのサイズが縮小され、各クリップボード結果ページの表示にかかる時間も短縮されます。 ページングでは、表示する結果の数を増やすために、次のページに移動することが必要となります。
- エンドユーザーの場合は、リクエスターのサイズが許容範囲内にとどまっていることを確認してください。 クリップボードのサイズが5MBを超えている場合は、取得したデータに不要なものが含まれていないかどうかを調べる必要があります。
- 廃止されたデータページと期限切れのデータページが削除され、メモリが定期的にクリアされていることを確認し、メモリリークをチェックしてください。
- リクエスターとスレッドで読み込みに時間のかかっているデータページを評価し、可能であればそのフットプリントを減らします。
- バッチリクエスタープール内のリクエスターの数をモニタリングして調整します。
Performance Detailsを使用して、クリップボードのサイズを確認し、メモリの使用状況を経時的にモニタリングします。
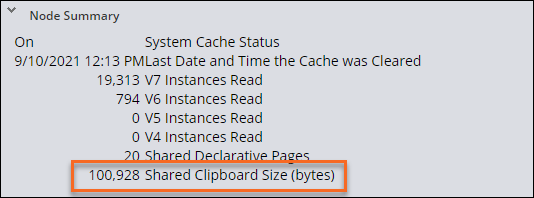
補足: プール内のリクエスターの数を変更するには、prconfig.xmlファイルのagent/threadpoolsize設定またはDSSを使用します。 スレッドレベルのページもモニタリングして、クリップボードの使用量を必要なデータのみに制限します。
アーカイブ
本番アプリケーションでは、ケースのデータ量が数百メガバイトのデータベースストレージを必要とするサイズにまで増大する場合があります。 ケースアーカイブを有効にして、非アクティブなケースをセカンダリストレージに移動します。 ケースをアーカイブする際に、Pega Platformは、Job Schedulersで設定されたさまざまなジョブを使用して、スタンドアロンのケースおよびケース階層の特定のアーティファクトをコピー、インデックス付け、およびパージします。 次のアーティファクトをアーカイブして、データベースのパフォーマンスを向上させることができます。
- 子ケース
- 宣言型インデックス
- ワーク履歴
- Pulse応答
- 添付ファイル
補足: データベースパフォーマンスの向上の詳細については、「Improving database performance」を参照してください。 アーカイブプロセスの詳細については、「The Case archiving process」を参照してください。
トリミングとパージ
Pega Cloud環境を使用している場合は、SQLクエリーツールまたはアクティビティを使用してテーブルをトリミングまたはパージできます。 パージは常にアーカイブの後に行われます。 まず、アーカイブに保存するソースプロダクションシステムのコピー(同じルールとデータスキーマを使用)であるデスティネーションアーカイブシステムを確立します。 アーカイブ後にパージすると、テーブルから行が削除されます。
Pega Platformには、Purge/Archiveウィザードも用意されています。このウィザードを使用するには、まずアクティビティを作成して、パージまたはアーカイブの基準を定義する必要があります。 そして、パージやアーカイブのアクティビティの予定を決めます。 Purge/Archiveウィザードは正式にサポートされなくなりました。 その代わりに、組織のデータベースツールを使用して、オンプレミスインスタンスのデータをアーカイブおよびパージすることをお勧めします。
注: 削除されたレコードを簡単に復元する方法はありません。パージは注意して行ってください。 データをパージするプロセスの詳細については、「ケースデータのアーカイブと消去」を参照してください。
以下のインタラクションで理解度をチェックしてください。
このトピックは、下記のモジュールにも含まれています。
If you are having problems with your training, please review the Pega Academy Support FAQs.