
業界基盤データモデルのメリット
Pegaの業界基盤データモデルでは、ゼロから論理データモデルを構築するのではなく、既存の論理データモデルを活用し、拡張できます。 Pegaには、ヘルスケア、通信およびメディア、ライフサイエンス、保険、金融サービス向けの業界データモデルが用意されています。 データクラスを自分で構築する代わりに、システムオブレコードのプロパティを業界のデータモデルのデータクラスとプロパティにマッピングできます。
業界基盤データクラスに、必要に応じて外部のシステムオブレコードからのプロパティを追加することができます。
Pegaの業界基盤データモデルには、関心の分離(SoC)という設計原則が適用されています。これは、ビジネスロジックとデータを取得するインターフェイスを分離しておくというものです。 ビジネスロジックは、データが必要となるタイミングや、データを取得した後のデータの処理方法を決定しますが、 インターフェイスがビジネスロジックを分離するため、データの取得方法がわからなくなります。
Pega Platformでは、データページがビジネスロジックとインターフェイスロジックを接続します。 次の図は、データページ、データクラス、データを取得する仕組みの関係を示しています。

この設計パターンにより、データモデルやアプリケーションの動作に影響を与えることなく、統合ルールを変更できます。
プロジェクトでは、業界基盤データモデルを直接拡張するのではなく、Enterprise Service Bus(ESB)専用データモデルの使用が義務付けられている場合があります。 ESBの目的は、バスにアクセスするクライアントが、バス上で宣伝されているどのサービスとも対話できる、正規データモデルを実装することです。
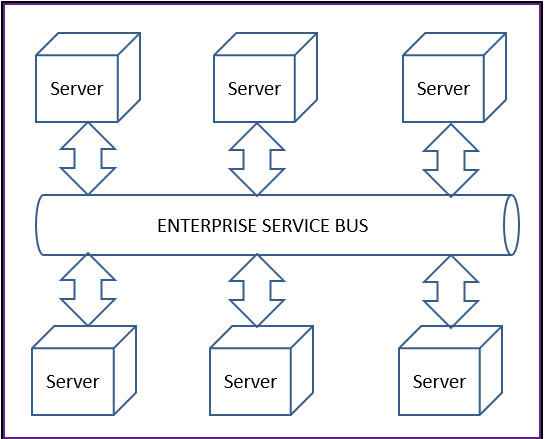
ESBを使用する状況では、Pega開発チームは正規データモデルを定義しませんが、 正規データモデルと基盤データモデル間のマッピングを維持する可能性はあります。
補足: この場合のベストプラクティスは、Pegaの開発チームが必要に応じて基盤データモデルを活用して拡張することです。 外部SORプロパティとPegaの基盤データモデルプロパティのマッピングはすべて、Pega開発チームがデータページを使用してPegaアプリケーション内で行う必要があります。
このトピックは、下記のモジュールにも含まれています。
If you are having problems with your training, please review the Pega Academy Support FAQs.