Queue processors and job schedulers
Pega Platform™ supports several options for background processing. You can use the queue processors, job schedulers, standard and advanced agents, service-level agreements (SLAs), wait shapes, and listeners to design background processing in your application.
Note: For better scalability, ease of use, and faster background processing, use job scheduler and queue processor rules instead of agents.
Queue processor
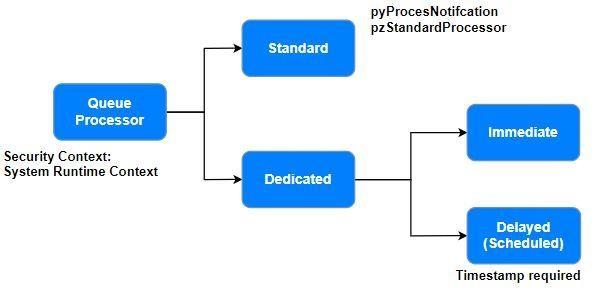
A queue processor rule is an internal background process that you configure for queue management and asynchronous message processing. Use standard queue processor rules for simple queue management or low-throughput scenarios, or use dedicated queue processor rules for higher-scaling throughput and customized or delayed processing of messages.
Pega Platform provides many default standard queue processors of which pzStandardProcessor is triggered internally to queue messages when standard is chosen as an option in the Type of queue section of the Queue-For-Processing method or the Run in background shape. A custom activity must be passed. Availability of this rule is set to Final to restrict changes. This queue processor is immediate and cannot be used in scenarios where delayed processing is required.
A queue processor rule allows you to focus on configuring the specific operations to perform in the background. Pega Platform provides built-in capabilities for error handling, queuing and dequeuing, and can commit conditionally when using a queue processor. Queue processors are often used in an application that stems from a common framework or is used by the Pega Platform itself.
All queue processors are rule-resolved against the context that is specified in the System Runtime Context. When configuring the Queue-For-Processing method in an activity, or the Run in Background step in a stage, it is possible to specify an alternate access group. It is also possible for the activity that the queue processor runs to change the Access Group. An example is the Rule-Test-Suite pzInitiateTestSuiteRun activity executed by the pzInitiateTestSuiteRun queue processor.
Use standard queue processors for simple queue management or dedicated queue processors for customized or delayed message processing. If you define a queue processor as delayed, define the date and time while calling through the Queue-For-Processing method or by Run in Background smart shape.
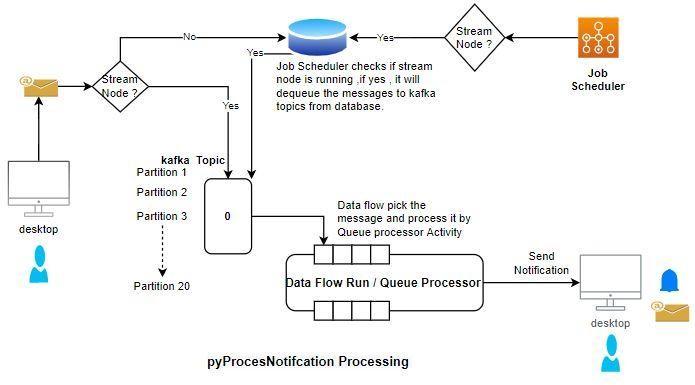
Queues are multi-threading and shared across all nodes. Each queue processor can process messages across 20 partitions, which means that queue processor rules can support up to 20 separate processing threads simultaneously with no conflict. Leveraging multiple queue processors on separate nodes to process the items in a queue can also improve throughput.
For example, suppose you have to send any notification. In that case, the pyProcessNotifcation queue processor is used as shown in the following image:
Performance has two dimensions: time to process a message and total message throughput. These can be improved by performing the following actions:
- Optimize the activity to reduce the time to process a message. Time to process a message depends on the amount of work done by the processing activity.
- Enhance total message throughput in the following ways:
- Scale-out by increasing the number of processing nodes. This setting applies only to on-premises users. For Pega Cloud® Services, a larger sandbox is required.
- Scale-up by increasing the number of threads per node, up to 20 threads per cluster.
As soon as a queue processor is created, a topic corresponding to this queue processor is created in the Kafka server. Based on the number of partitions mentioned in the server.properties file the same number of folders are created in the tomcat\Kafka-data folder.
At least one stream node is necessary for messages to be queued to the Kafka server. If you do not define a stream node in a cluster, the items are queued to the database, and then these items are processed when a stream node is available.
Default queue processors
Pega Platform provides three default queue processors.
pyProcessNotification
The pyProcessNotification queue processor sends notifications to customers and runs the pxNotify activity to calculate the list of recipients, the message, or the channel. The possible channels include an email, a gadget notification, or a Push notification.
pzStandardProcessor
You can use the pzStandardProcessor queue processor for standard asynchronous processing when:
- Processing does not require high throughput, or processing resources can be slightly delayed.
- Default and standard queue behaviors are acceptable.
This queue processor can be used for tasks such as submitting each status change to an external system. It can be used to run bulk processes in the background. When the queue processor resolves all the items from the queue, you receive a notification about the number of successful and failed attempts.
pyFTSIncrementalIndexer
The pyFTSIncrementalIndexer queue processor performs incremental indexing in the background. This queue processor posts rule, data, and work objects into the search subsystem as soon as you create or change them, which helps keep search data current and closely reflects the content of the database.
Job scheduler
Use a job scheduler rule when there is no requirement to queue a reoccurring task. Unlike queue processors, the job scheduler must decide which records to process and establish each record’s step page context before working on that record. For example, suppose you need to generate statistics every midnight for reporting purposes. In that case, the output of a report definition can determine the list of items to process. The job scheduler must then operate on each item in the list.
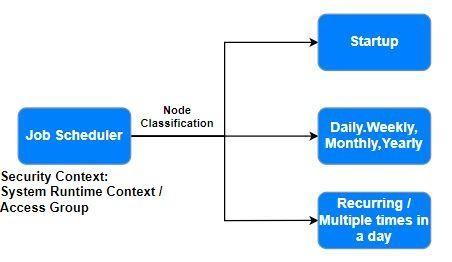
If any specific context is required for an activity, select Specify access group to provide the access group.
If System Runtime Context is required for an activity (for example, use the same context for the job scheduler and activity resolution), select Use System Runtime Context.
A job scheduler can run on one or more nodes in a cluster or any specific node in a cluster. To run multiple job schedulers simultaneously, configure the number of threads for the job scheduler thread pool by modifying the prconfig.xml file. The default value is 5. The number of threads should be equal to the number of job schedulers that run simultaneously.
Unlike queue processors, a job scheduler needs to decide whether a record needs to be locked. It also must decide whether it needs to commit records that have been updated using Obj-Save. If a job scheduler creates a case or opens a case with a lock and causes it to move to a new assignment or complete its life cycle, the job scheduler does not have to issue a commit.
Default job schedulers
Pega Platform provides the many default job processors that can be useful in your application.
Node cleaner
The node cleaner cleans up expired locks and outdated module version reports.
By default, the node cleaner job scheduler (pyNodeCleaner) runs the Code-pzNodeCleaner activity on all the nodes in the cluster.
Cluster and database cleaner
By default, the cluster and database job scheduler (pyClusterAndDBCleaner) runs the Code-.pzClusterAndDBCleaner activity on only one node in the cluster, once every 24 hours for housekeeping tasks. This job purges the following items:
- Older records from log tables
- Idle requestors for 48 hours
- Passivation data for expired requestors (clipboard cleanup)
- Expired locks
- Cluster state data that is older than 90 days.
Persist node and cluster state
pyPersistNodeState saves the node state on node startup.
Cluster state data is saved once a day by the pyPersistClusterState job scheduler.
The pzClusterAndDBCleaner job scheduler purges cluster state data that is older than 90 days.
Standard agent
Caution: Consider using a job scheduler or queue processor instead of an agent.
Standard agents are preferable when you have items that are queued for processing. Standard agents allow you to focus on configuring the specific operations to perform. Pega Platform provides built-in capabilities for error handling, queuing and dequeuing, and commits when using standard agents.
By default, standard agents run in the security context of the person who queued the task. This approach can be advantageous in a situation where users with different access groups leverage the same agent. Standard agents are often used in an application with many implementations that stem from a common framework or in default agents provided by Pega Platform. The access group setting on an agents rule applies to advanced agents only, which are not queued. To always run a standard agent in a given security context, you need to switch the queued access group by overriding the System-Default-EstablishContext activity and invoke the setActiveAccessGroup() java method within that activity.
Queues are shared across all nodes. Leveraging multiple standard agents on separate nodes to process the items in a queue can improve the throughput.
Tip: There are several examples of default agents using the standard mode. One example is the agent processing SLAs ServiceLevelEvents in the Pega-ProCom ruleset.
Advanced agent
Use advanced agents when there is no requirement to queue and perform a reoccurring task. Advanced agents can also be used when there is a need for more complex queue processing. When advanced agents perform processing on items that are not queued, the advanced agent must determine the work that is to be performed. For example, if you need to generate statistics every midnight for reporting purposes, the output of a report definition can determine the list of items to process.
Tip: Several examples of default agents using the advanced mode, including the agent for automatic column population pxAutomaticColumnPopulation in the Pega-ImportExport.
When an advanced agent uses queuing, all queuing operations occur in the agent activity.
Tip: The default agent ProcessServiceQueue in the Pega-IntSvcs ruleset is an example of an advance agent processing queued items.
When running on a multinode configuration, configure agent schedules so that the advanced agents coordinate their efforts. To coordinate agents, select the advanced settings Run this agent on only one node at a time and Delay next run of agent across the cluster by specified time period.
Default agents
When Pega Platform is initially installed, many default agents are configured to run in the system (similar to services configured to run in a computer operating system). Review and tune the agent configurations on a production system because there are default agents that:
- Are unnecessary for most applications because the agents implement legacy or seldom-used features.
- Should not run in production.
- Run at inappropriate times by default.
- Run more frequently than needed, or not frequently enough.
- Run on all nodes by default but should run on only one node.
For example, by default, there are several agents configured to run the Pega-DecisionEngine in the system. Disable these agents if decisioning does not apply to the applications. Enable some agents only in a development or QA environment, such as the Pega-AutoTest agents. Some agents are designed to run on a single node in a multinode configuration.
For a complete review of agents and their configuration settings, see Agents and agent schedules. Because these agents are in locked rulesets, they cannot be modified. To change the configuration for these agents, update the agent schedules generated from the agents rule.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?