Reporting and data warehousing
Overview
Organizations often want to combine data from web applications, legacy applications, and other sources to make decisions in real time or near real time. Many organizations use business intelligence software to collect, format, and store the data and provide software to analyze this data to make these decisions.
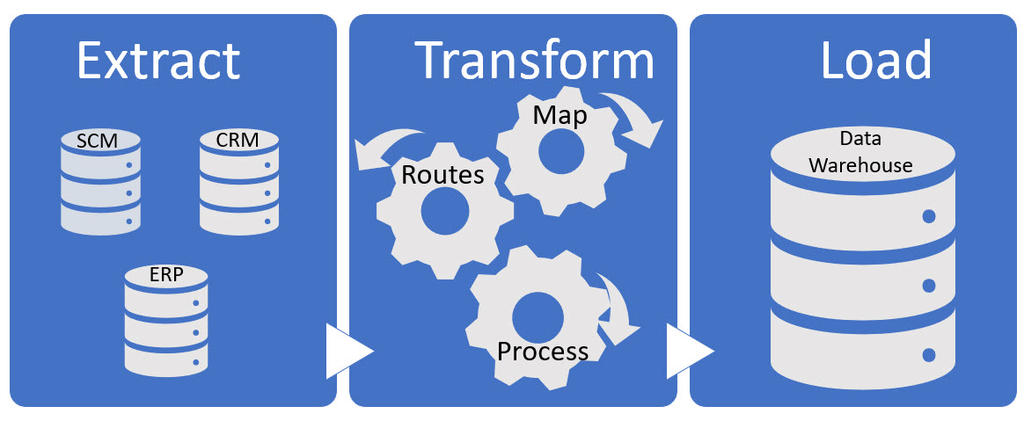
A data warehouse is a system used for reporting and data analysis. The data warehouse is a central repository of integrated data from one or more separate sources of data. The extract, transform, and load (ETL) process prepares the data for use by the data warehouse. The following conceptual image illustrates a typical end-to-end process of extracting data from systems of record and storing the data in the warehouse, then making that data available to reporting tools.
The key factor is to determine whether you design your reports in the Pega application or leverage an external reporting tool impacts application performance. For example, if your reporting requirements state that you need to show how many assignments are in a workbasket at any given time, creating a report on the assignment workbasket table is appropriate. If you analyze multiple years of case information to perform some trending analysis, use reporting tools suited for that purpose instead. You can provide a link to those reports from the end user portal in the Pega application.
Business Intelligence Exchange
Business Intelligence Exchange (BIX) allows you to extract data from your production application and format it to make it suitable for loading into a data warehouse. BIX is an optional add-on product consisting of a ruleset and a standalone Java program run from a command line. BIX data from the BIX process can be formatted as XML or comma-separated (CSV) or can be output directly to a database. The following diagram depicts extracting the data from the Pega database and preparing the data for use by downstream reporting processes.
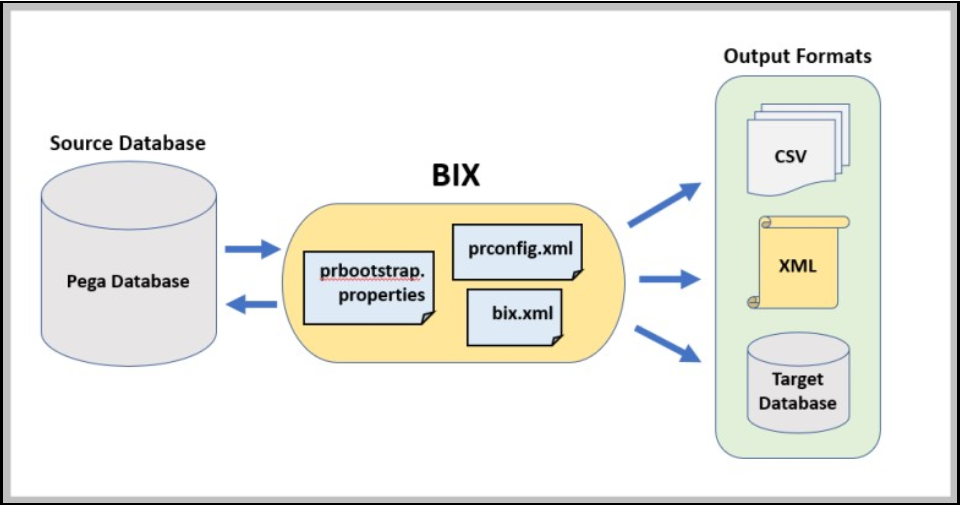
For more information on BIX, see the help topic Business Intelligence Exchange.
Elasticsearch
To improve report generation performance, you can run report definitions against Elasticsearch indexes instead of using SQL queries directly against the database. Running report definitions against Elasticsearch indexes is disabled by default and does not apply to reports with features that Elasticsearch does not support. If a report query cannot be run against Elasticsearch indexes, Pega Platform™ automatically uses an SQL query.
Elasticsearch is eventually consistent storage. By enabling report definitions to run against Elasticsearch indexes, you indicate that strong consistency is not required.

Data retrieval preference can be set dynamically by setting the value for pyContent.pyGetCachedDistinctValue and can be used in UI component that supports virtual reports or pass this parameter to an activity that runs the report.
Reports that use string comparison operators in filters can now run queries against Elasticsearch instead of querying the database. The following operators are supported for Elasticsearch queries:
- Starts with, Ends with, Does not start with, and Does not end with
- Contains and Does not contain
- Greater than, Less than, Greater than or equal, and Less than or equal
If a query cannot be run against Elasticsearch, the query is run against the database (for example, if the query includes a join). To determine if a query was run against Elasticsearch, use the Tracer tool and enable the Query resolution event type.
To improve the chances that Elasticsearch is selected as the report’s source, Select "Use dedicated index" within the custom search properties rule form.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?