
Design patterns
Design patterns are definitions of reusable components or solution patterns applied to solve common recurring issues. As part of a center of excellence (COE) team, a Lead System Architect (LSA) uses case design patterns that are specific to their business domain, which helps the team quickly build reusable and maintainable solutions.
As an LSA, when we start application design, we use design thinking techniques to break customer journeys into smaller, more manageable pieces called Microjourneys™. These microjourneys can be implemented using the Pega Express™ delivery approach. Follow the discussion at Pega Express Values and best practices.
Before we go for actual implementation, we should be designing and documenting the solution by using the design patterns. Here are few design patterns for case interactions:
- Divide and conquer (most common)
- Data instance first
- Data instance after
- Limited availability and concurrency
- Parallel case processing
Divide and conquer
Divide and conquer is a well-known computational problem-solving algorithm. The algorithm splits the work to perform into smaller, independently solvable units, which, in turn, the algorithm can split into even smaller units. When each child unit of work completes, it notifies their parent unit of work. When the final child unit of work of a parent receives a notification, that parent then notifies its parent, and so on. Eventually, the parent that does not have any parent, meaning the top-level case, observes that every child unit of work is complete. When that occurs, the algorithm halts.
The significant benefit of the divide-and-conquer approach is that the algorithm can solve sibling units of work in parallel, and this significantly reduces the overall time to complete the work compared to sequential processing. This approach also provides a more significant opportunity for reuse.
In the business processing realm, a major benefit of the divide-and-conquer approach is that the algorithm can route different units of work to the appropriate people, groups, or work queues with the proper skills to accomplish the work efficiently. Established goals and deadlines can help to complete the work and visualize the degree to which work is or is not complete relative to a complicated case such as a claim.
The following diagram shows a sample representation of the divide-and-conquer design pattern in the context of a Booking application context. The diagram demonstrates how the Event Booking case uses the divide-and-conquer case design pattern to complete the work of different child cases in parallel. An Event Booking case can produce Hotel Booking, Weather, Parking, and Shuttle child cases. The Event Booking case can be resolved when every child case is resolved.
Data instance first
The data-instance-first design pattern demonstrates how the data related to a case persists before creating a case.
For example, when using mashup, it is unnecessary to create a case immediately. Instead, You can persist case data before the case is created. In this example, a mashup interface is configured as a "Display a page" action instead of a "Create a new case" action.
If the process execution is by a single actor and concerns the capture and persistence of the data, then the data instance first is the best design pattern to apply. You can use Pega UI page concept to capture the data. UI page can have buttons (or another control for e.g., Link/Image etc.) that trigger the utility to persist the captured data. If required, you can create a case after the data from the View data class is persisted. You can invoke a Pega API "cases" POST method to create the case, or you can call the Create case utility, when required to create case instances.
The following diagram shows how a case does not need to be created before creating a data instance that references the case or that the case references. With the data-instance-first design pattern, you can persist the data instance first, followed by the creation of the case. Data can be captured using UI pages or a Pega Mashup and then processed and persisted. If necessary, the data can be updated. If required, you can create a new case instance.

Data instance after
The data-instance-after design pattern in a Pega Platform™ is similar to the object-action interface for core programming languages. In this design pattern, users perform an action on an existing object or select an object.
An example implementation of a data-instance-after design pattern is a Gymnastics business scenario. Enrolled judges are assigned to a Gymnastics competition case to provide a score in this business scenario. The average score from two judges is the final score. The Gymnastics competition case is the existing case; by the time judges are assigned, you cannot assign judges to non-existing or non-active gym competitions. It is unnecessary to make Assign judges process as a child case (or sibling case) to a Gymnastics competition case. The best way to implement it is to use UI landing pages that display the list of judges; users select two judges and associate them with the competition case.
This diagram is a pictorial representation of existing case instance updated by action such as update or add or delete, this diagram also represents scenario where existing case instances refer data stored outside of the case.

Limited availability and concurrency
The limited-availability-and-concurrency case design pattern is a variant of the object-action approach pattern. Users want to associate several items, such as data or cases, with an existing item, such as a case.
For example, customers can make reservations in an application for a ferry that transports vehicles. A Trip case represents the ferry. Customers apply to reserve space on a particular trip for themselves and their vehicle.
The limited-availability-and-concurrency design pattern differs in that:
- There is limited capacity. For example, there is a limit to the number of passengers and vehicles that the ferry can carry.
- Concurrency management is critical.
Regarding concurrency management, suppose two customers each make reservations simultaneously for the same trip. There is only enough remaining capacity to honor one of the reservations; the other reservation attempt goes to the end of a waiting list.
Are Reservation child cases the best solution to this problem?
If the capacity of a ferry is 500 passengers, it does not make sense to create that many child cases. A simpler and faster approach is to insert or update Reservation data instances. Reservation data instances reference the Trip case. Write a utility to check the availability of seats or any other required validations. All these operations occur at the data instance level, and case instance updates happen only once at the end of the scenario. In this example, update the Trip case after all seats are filled up or at the departure time of the trip.
The time it takes to write a single row to a single database table is shorter compared to the time that it is necessary to run a lock-query-save-commit-unlock process.
The following diagram shows an example of one or more limitations that regard the number of data instances a case can manage. Because multiple concurrent users can access the data instances, users maintain a data instance queue to identify the precise order in which users enter, update, or delete data instances. Data instances are processed in the correct sequence, and availability is validated for each before persisting them or updating an associated case instance. When the availability becomes low, and the concurrency is high, measures to avoid over-consuming the capacity limits of the case are necessary.
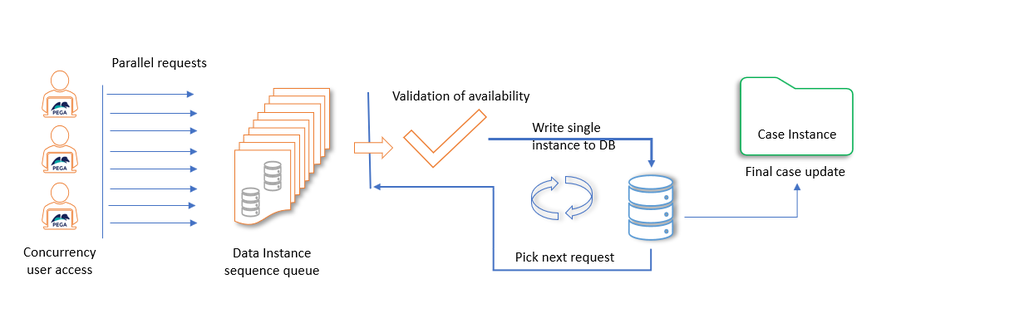
Parallel case processing
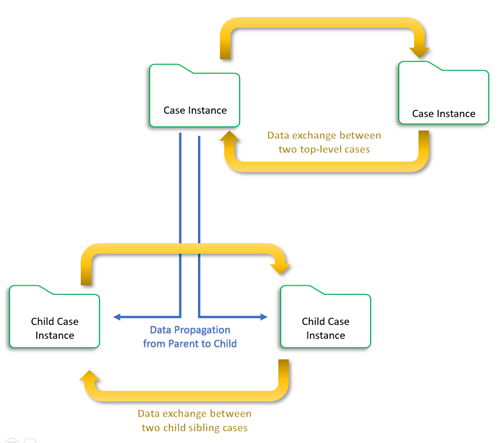
Sibling cases that interact with one another at the same level in the case hierarchy, such as two top-level cases or two child cases with the same parent case, represent the parallel-case-processing design pattern.
For example, Benefits Enrollment and Paycheck are two child cases of an Onboarding case. If the two cases require users to modify an employee record, and both cases require the updated data, then the decision to implement the interacting cases as a sibling relationship requires planning on how best to implement that relationship. Possibilities include using the Update a case flow shape, a common database table, or the Queue-For-Processing method in an activity.
There are situations where a parent/child relationship between two cases is unsuitable. Instead, the two cases are at the same hierarchy level (siblings) and need to perform an update, either one-way or bi-directional. The following diagram shows how the exchange of data can occur between two-top level cases or between two child-sibling cases after the system propagates the data to them from their parent case.
An alternate design pattern - Data instance only
Microjourney can be implemented with one of the case design patterns discussed above or can be implemented with data-instance-only design pattern.
The data-instance-only design pattern demonstrates that some functional requirements just need capturing of the data and persisting in the required format at the required location. The persisted data can be referenced and processed by other objects.
For example: You take a functional requirement to capture and display the office locations of a global mobile sales and service company. The office locations may be added / deleted / modified / updated by the office administrators whenever the company is extending (or changing) its service locations. As per the business scenario, ‘office location’ is an important attribute required to be selected by the customer when raising a service request and ‘office location’ contributes for the calculations of service fee and tax to be paid for the services utilized. This business scenario can be easily implemented with data-instance-only design pattern.
Following diagram shows the capturing of data using different channel and persisting into the system. Captured data will be referred by other objects, processed as part of case lifecycle, but will never be converted as case type.

Check your knowledge with the following interaction:
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?