Hazelcast
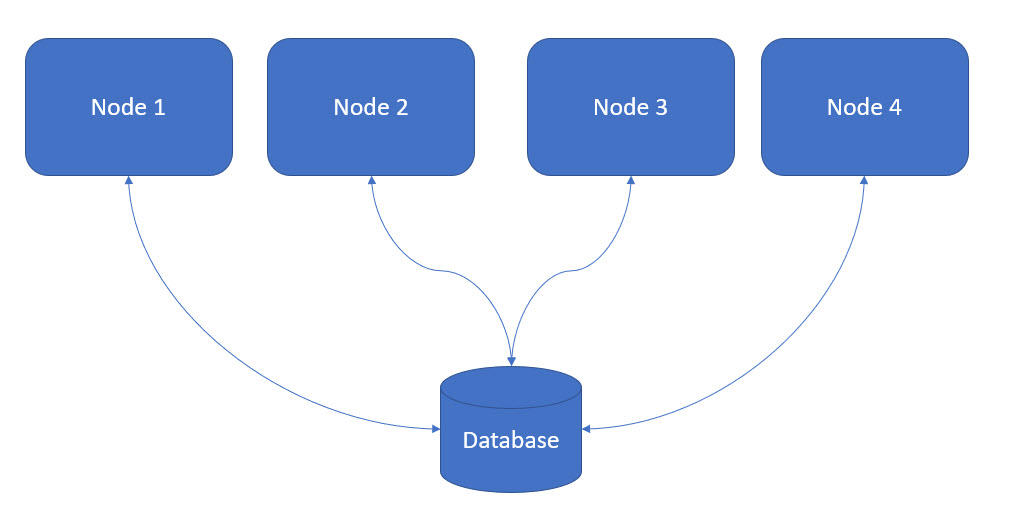
Many applications are deployed across several applications or servers in a cluster and communicate with a single relational database in the application architecture, as shown in the following image:
This issue can be resolved by making use of the cache that is embedded in each node. If the data is already in the cache, the request to the database is skipped, and the data from the cache is used; if the data isn't in the cache, the request to the database is initiated, and the data fetched will be used.
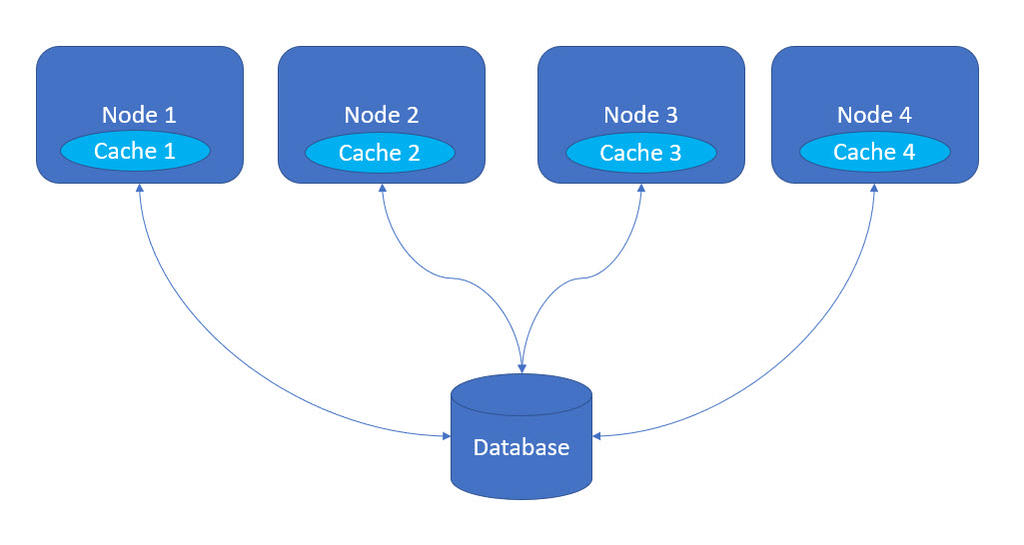
With this approach, there can be a cache consistency issue whenever data is updated by an application that is deployed on app server1. The data in cache1 and database are consistent, but the cache2, cache3, cache4 do not have updated data.
The inconsistency problem can be solved by using an in-memory data grid. A data grid is a collection of servers that operate together in a distributed environment to manage data and related tasks. An in-memory data grid (IMDG) is the data that is entirely stored in Random Access Memory (RAM) with key-value pairs.
Most enterprises that previously avoided adopting in-memory technology because of the pricing are now changing the architecture of their systems to take advantage of in-memory technology's low-latency transaction processing. Due to the significant decrease in the price of RAM, it is now cost-effective to load the whole operational dataset into memory, resulting in a much-improved performance.
The following list contains popular in-memory data grid (IMDG) implementations:
- Hazelcast
- Infinispan
- Red Hat JBoss Data Grid
- Ncache
Hazelcast
Hazelcast is designed for environments where the power of in-memory computing can be used to accelerate applications that require low latency, high throughput, horizontal scaling, and security. Hazelcast can run embedded in every node but also supports a client-server topology.
Pega Platform™ low-level features such as agents, Job Scheduler, and REST service rules use Hazelcast to cache or store the data.
Hazelcast IMDG is an ideal choice for services running on a cloud platform such as Kubernetes, where service replicas can quickly scale up and down.
Pega Platform deployments with Hazelcast can be used in two modes: embedded or client server.
Embedded
Embedded hazelcast is recommended If your application requires high-performance computing and a huge amount of task executions. Every Pega node connects to all other Pega nodes and forms a cluster. This deployment option has low-latency data access.

Client server
Hazelcast in client-server mode is an in-memory cache management platform that can provide greater speed and scalability in large multi-node clusters. Hazelcast supports high-performance transactions, real-time streaming, and fast analytics in a single, comprehensive data access and processing layer. This client-server model is more stable for large clusters.
Client-server mode is a clustering topology that separates Pega Platform processes from cluster communication and distributed features. Client-server mode clustering technology has separate resources and uses a different JVM than the Pega Platform. The client nodes are Pega Platform nodes that perform application jobs and call the Hazelcast client to facilitate communication between Pega Platform and the Hazelcast servers. The servers are stand-alone Hazelcast servers that provide base clustering capabilities, including communication between the nodes and distributed features.
Hazelcast Management Center
Hazelcast provides a management center tool to manage and maintain the overall state of cluster members.
Management Center can be used for the following tasks:
- Analyze and browse through the data structures
- Take thread dumps from nodes.
- Update map configurations.
- Monitor caches.
Management Center provides useful operations features, such as the ability to clear distributed data or shut down members. However, a best practice is to restrict these features to:
- Prevent modification of the cluster by customers while it is in use as doing so may cause instability.
- Management Center allows users to view data in Hazelcast caches and maps. In HIPPA compliant environments, this may not be legal.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?