
Ingesting customer data into Pega Customer Decision Hub
To make the best, most relevant next-best-action decisions, Pega Customer Decision Hub needs to have up-to-date data about the customers, their demographics, product holding, activity data, and other information that may be stored in third-party systems.
Because this information is updated frequently, you must ensure that the updates propagate to Pega Customer Decision Hub. Not all data is updated with the same regularity. Based on the frequency of updates, customer data can be classified as non-volatile or volatile data.
Non-volatile data include data attributes, which are updated at regular intervals, such as on a daily, weekly, or monthly basis.
Volatile data are typically updated in real-time, such as in transactional updates, and mobile and web click-throughs.
A key design principle to follow is that customer data required by Pega Customer Decision Hub should be available at rest. Avoid attempting to make real-time calls to access the data at the time of making a next-best-action decision, because the end-to-end time to make a decision will have dependencies on the performance of these real-time calls.
For processing non-volatile data, it is recommended that you establish a file transfer mechanism using secure-file-transfer-protocol (SFTP) to support any required batch transfers. For volatile data, it is recommended to establish services that process those updates as they occur, to ensure optimum results. Details and best practices for managing data can be found in the Pega Customer Decision Hub Implementation Guide.
After performing the data mapping workshop, and after the data is transformed into a structure that matches the customer data model as defined in the context dictionary, a key set of activities must be completed in order to ingest data.
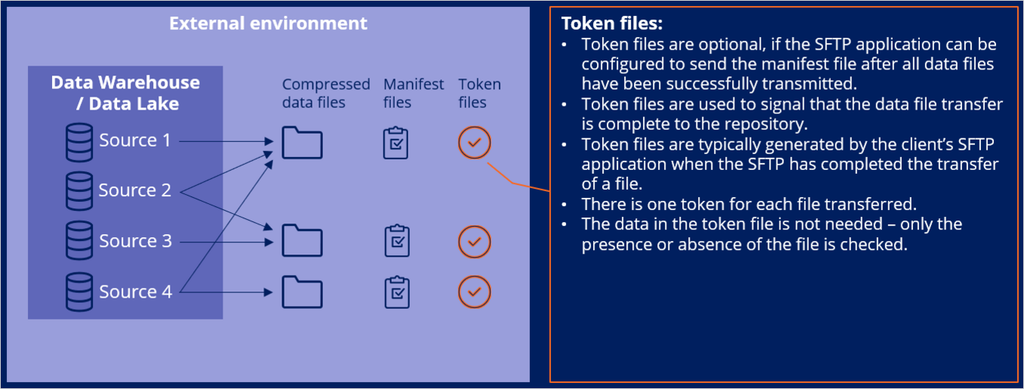
Ingesting data into Pega Customer Decision Hub typically involves three types of files: data files, manifest files, and token files.
The data files contain the actual customer data and are generated by the client's extraction-transformation-load (ETL) team. The files may contain new and updated customer data as well as data for purging or deleting existing records. A data file's column structure should match the data model in Customer Decision Hub, to avoid complex mapping and data manipulation.
Best practice is to divide large files into multiple smaller files to allow parallel transfer and faster processing. Files can be in CSV or JSON format and can be compressed. File encryption is also supported.
The manifest files are XML files that contain metadata about the data files being transferred. There is one manifest file for each ingestion or purge file to be transferred.
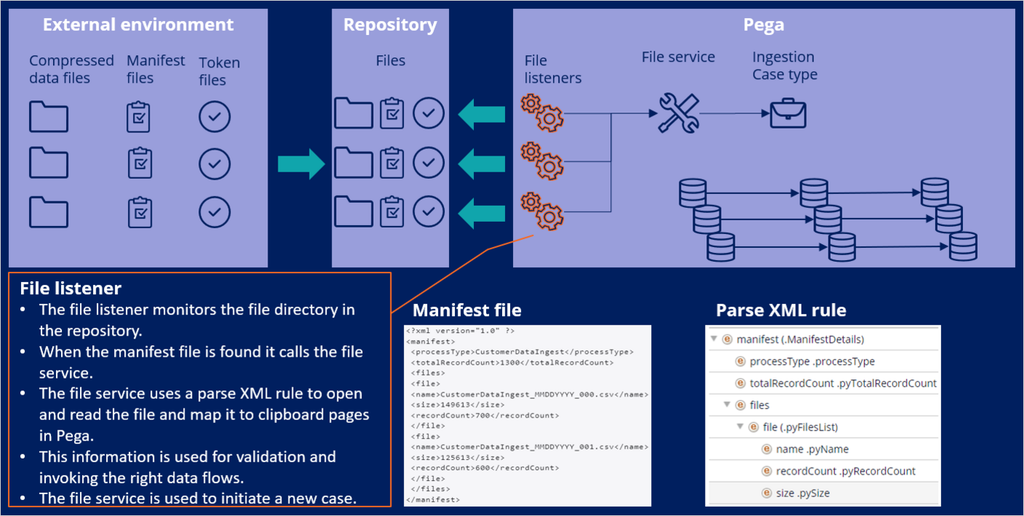
The file listeners are configured to listen to the manifest files in order to initiate data ingestion. The processType attribute in the manifest XML files is used to determine which data flows to execute, as well as other attributes such as recordCount and size, which are used for file and upload validations.

The token files are used to signal that the data file transfer is complete. This type of file is optional, and only necessary if a Secure File Transfer Protocol application cannot be configured to transfer the manifest files after the actual data file transfer is complete.
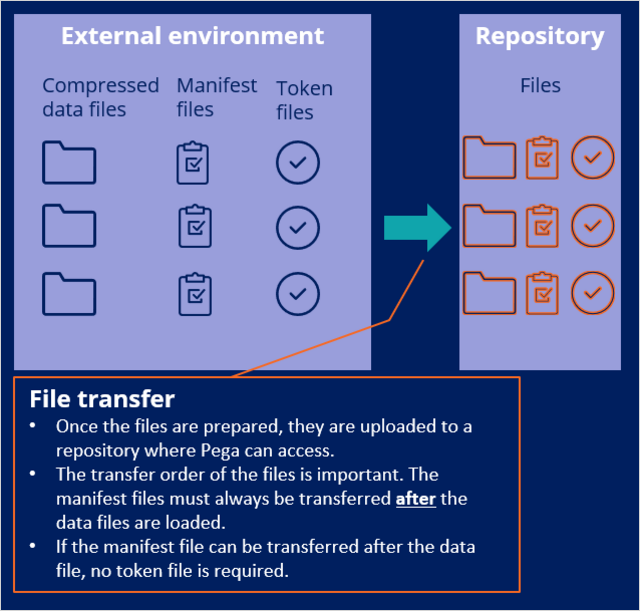
Once the ETL team prepares the files, they are uploaded to a repository that Pega can access. The manifest files must be transferred last (after the data files), to ensure that the actual processing does not start before the data upload is complete.
The file listeners monitor the file directory in the repository. When files that arrive in the directory match the pattern that the file listener is listening for, the listener moves the files into the work_<name of listener>/completed directory and calls the file service. The file service uses a parse XML rule to open and read the manifest file, evaluate each input record, divide the record into fields, and then write the fields to the clipboard. A service activity then processes the data in the case, to create a new case.
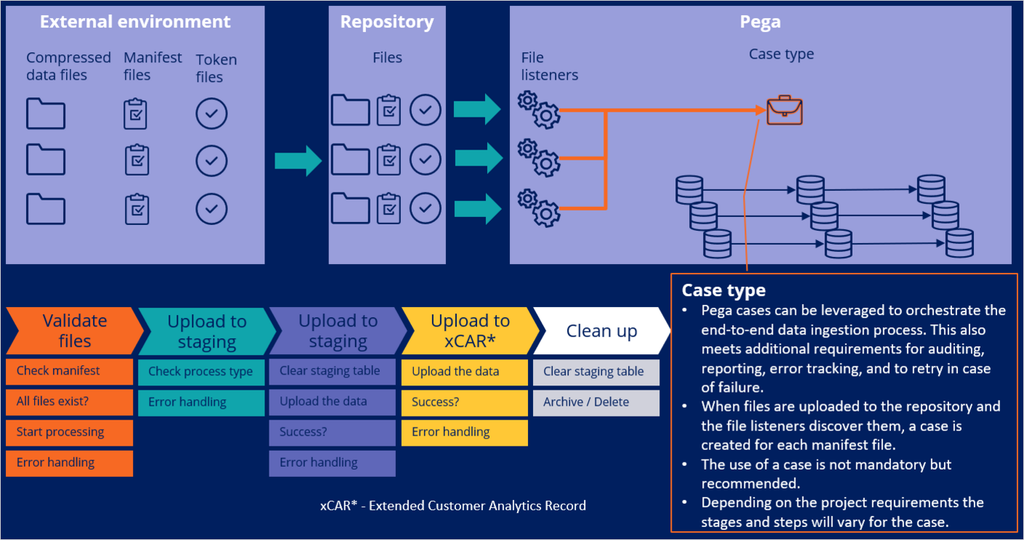
The service file initiates the process by starting an ingestion case type. Within the case type, you can specify when to start the ingestion process and how to handle errors. Typically, the process starts with validating the files and ensuring the contents match the manifest. Once the files and counts are validated, the files are first staged into a staging dataset, then uploaded to the customer analytical data model. The exact stages and steps are dependent on project requirements and can be organized accordingly.
Data sets are used to access different types of stored data and to insert / update the data into various destinations. Data flows are scalable and resilient data pipelines that are used to ingest, process, and move data from one or more sources to one or more destinations. In a data ingestion case, typically there are three types of data sets that are used. A file data set is used to access the data in the repository. A Decision Data Store (DDS) data set is used to stage the data for validations, and a database data set to store the data in corresponding tables in the database. To read from the file data set, and to write to the staging data set, a data flow is created. Similarly, to read from the staging data set and to write to the database, another data flow is created. For each processType, a new set of artifacts must be created. Using the processType in the manifest file, the case determines which set of data flows to start.
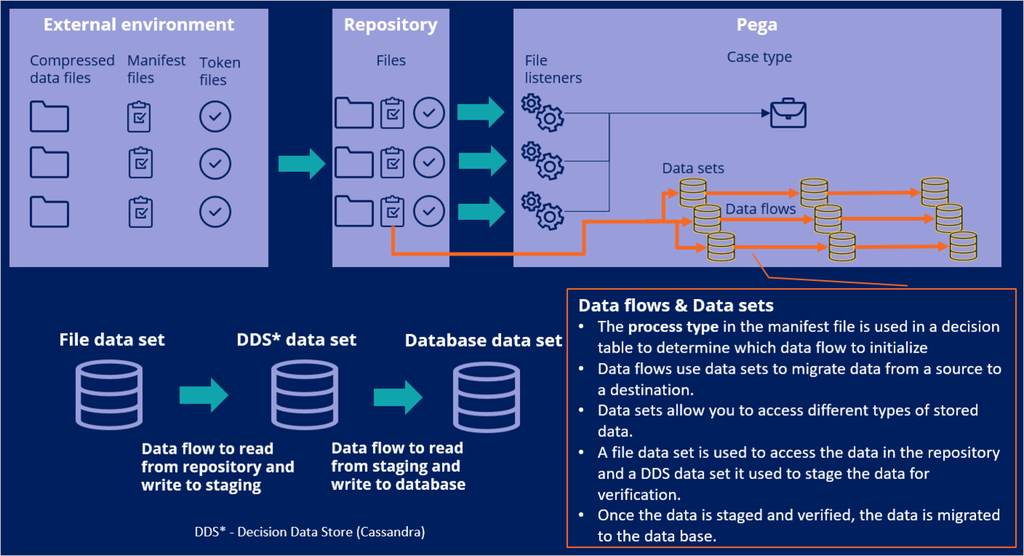
In summary, the data that will be loaded to Pega is first structured to match the data model in Pega and then compressed. For each compressed file, a manifest file is created that has information about the file it represents. In some cases, an empty token file can be used to initiate the load process. The files are loaded to a repository to which Pega has access. File listeners within Pega continuously access the repository for the manifest files that they listen for. When the file is found, the ingestion process starts.
Case types are a great way to streamline and automate the flow of files from the repository into their destinations, as the process is clearly visible and provides various error handling options.
After a file is found in the repository, a Pega case is created. This process flow in the case triggers a set of data flows that parse the data and move it from one place to another. Typically, the data is first staged for validation checks, then moved to its destination. Finally, a cleanup process is recommended to remove unwanted data from the staging data sets.
This Topic is available in the following Module:
If you are having problems with your training, please review the Pega Academy Support FAQs.
Want to help us improve this content?